引言
RAG 的效果,除了 Prompt、检索算法、Embedding 模型之外,还有 Chunking 分块策略。
什么是分块(Chunking)
把大块文本拆分,使得文本数据更容易管理处理,进行嵌入,从而提升从向量数据库中召回内容的相关性准确性。分块过程中有 2 个概念“chunk_size”块的大小,“chunk_overlap” 重叠窗口。

为什么分块
- 大模型上下文窗口限制:无法一次处理超长文本。
- 检索的信噪比:分块过大时无关内容会稀释信号、降低相似度判别力;分块过小时语境不足、容易“只命中词不命中义”。合适的块粒度可在召回与精度间取得更好平衡,既覆盖用户意图,又不引入多余噪声。在一定程度上提升检索相关性的同时又能保证结果稳定性。
- 语义连续性:防止段落的整体语义被拆分时出现语义切断,需要在连续的块中间设置适度的 chunk_overlap,以提升答案的连贯性与可追溯性。
所以合适的分块优势如下:
- 较小的文本段落更容易进行嵌入和检索,提高模型处理的效率。
- 分块后的文本能更精确地匹配用户查询,提高了内容召回的准确性,获得相关性更高的结果。
不恰当的分块策略会导致:
- 上下文断裂
- 关键信息被拆散(如定义与解释分离)
- 表格/代码/标题结构破坏 -检索命中但无法支撑答案,甚至引发幻觉
高质量分块则:
- 尊重自然语义边界(段落、标题、列表、代码块等)
- 设置适度重叠(chunk_overlap)以保持上下文连续(类似往期回顾)
- 保留元数据(如章节路径、来源位置),便于追溯与重排。
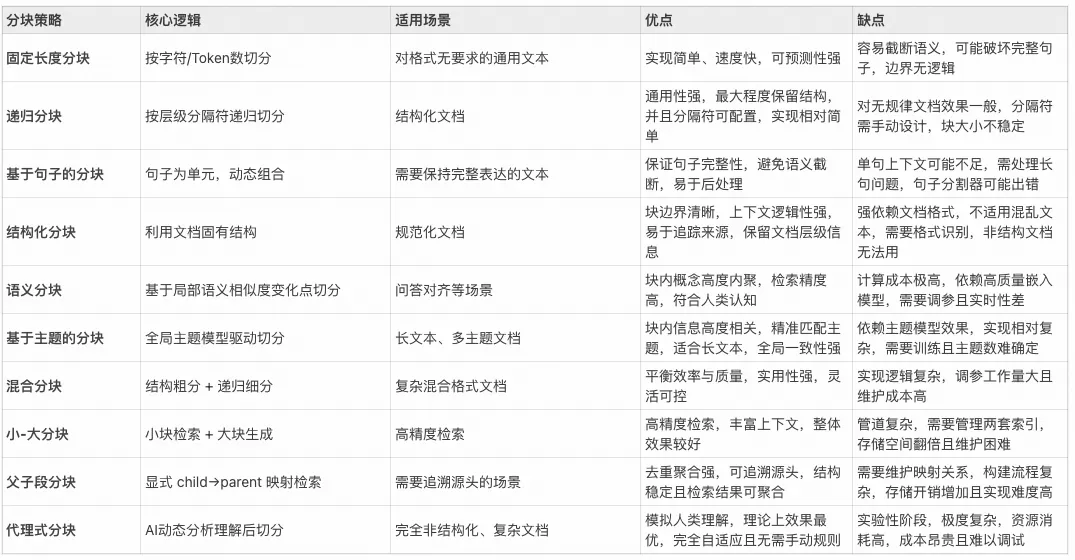
常见分块策略
基础分块
基于固定长度分块
按预设字符数 chunk_size 直接切分,不考虑文本结构。
- 优点:简单直接
- 缺点:破坏语义边界
基于句子分块
先按句子切分,再将若干句子聚合成满足 chunk_size 的块,保证句子基本语义完整。
- 优点:句子边界基本保留,完整性好
- 缺点:句子过短会导致分块过短,可能导致语境不足、容易“只命中词不命中义”
基于递归字符分块
给定一组由“粗到细”的分隔符(如标题 → 段落 → 换行 → 空格 → 字符),自上而下递归切分,在不超出 chunk_size 的前提下尽量保留自然语义边界。
- 优点:在“保持语义边界”和“控制块大小”之间取得稳健平衡,对大多数文本即插即用。
- 缺点:分隔符配置不当会导致块粒度失衡,对于格式化文本如表格、代码效果一般。
结构感知分块
利用文档固有的结构作为分块边界,逻辑清晰、可追溯性强,能在保证上下文完整性的同时提升检索信噪比。
结构化文本分块
和递归字符分块比较像,以标题层级(H1–H6、编号标题)或语义块(段落、列表、表格、代码块)为此类型文档的天然边界,对过长的结构块再做二次细分,对过短的进行相邻合并。
记得对 PDF/HTML 先去噪(页眉页脚、导航、广告等),避免把噪声索引进库。

对话式分块
在客服对话、访谈、会议纪要、技术支持工单等多轮交流中,设定一个滑动会话窗口存储若干条会话记录来支持上下文
举例:
|
|
1️⃣ 分块阶段
✅ 分块原则
- 每轮 = 用户发言 + 客服回复(构成一个完整交互单元)
- 若连续多轮围绕同一话题(如“订单取消”),可合并为一块
- 最大块长度控制(如 ≤ 400 字),避免过长
✅ 分块结果(3 个 chunk)
- Chunk 1(订单查询 + 发货状态)
|
|
- Chunk 2(订单取消 + 地址修改)
|
|
- Chunk 3(产品功能咨询)
|
|
2️⃣ 检索阶段:邻接扩展(Context Expansion)
假设用户提问:“我的第二个订单能取消吗?”
首先向量检索命中最相关块:Chunk 2(包含“#123789 可以取消”) 然后邻接扩展(取前后各 1 轮):向前扩展:Chunk 1(了解用户背景:刚问过第一单),向后扩展:Chunk 3(无关,不扩展) 最终大模型 不仅知道“能取消”,还理解这是用户的“第二单”,回答更自然:“您今天下的第二笔订单 #123789 尚未发货,已为您成功取消。
语义与主题分块
不依赖文档的物理结构,而是依据语义连续性与话题转移来决定切分点,尤其适合希望块内高度内聚、块间清晰分界的知识库与研究类文本。
语义分块
对文本先做句级切分,计算句子或短段的向量表示,当相邻语义的相似度显著下降(发生“语义突变”)时设为切分点。这就有点类似机器学习了,适用于专题化、论证结构明显的文档、白皮书、论文、技术手册、FAQ 聚合页

主题分块
利用主题模型或聚类算法在宏观话题发生切换时进行切分,更多的关注章节级、段落级的主题边界。该类分块策略主要适合长篇、多主题材料。
高级分块
小-大分块
简单来说就是见微知著、以小见大,先用“小粒度块”(如句子/短句)做高精度召回,然后定位到最相关的微片段,然后再将其“所在的大粒度块”(如段落/小节)作为上下文送入 LLM,以兼顾精确性与上下文完整性。

父子段分块
将文档按章节/段落等结构单元切成“父块”(Parent),再在每个父块内切出“子块”(通常为句子/短段或者笃固定块)。然后为“子块”建向量索引以做高精度召回。当检索时先召回子块,再按 parent_id 聚合并扩展到父块或父块中的局部窗口,兼顾最后召回内容的精准与上下文完整性。
与“小-大分块”的关系
小-大分块是检索工作流(小粒度召回 → 大粒度上下文); 父子段分块是数据建模与索引设计(显式维护 parent–child 映射)。 两者强相关、常配合使用:父子映射让小-大扩展更稳、更易去重与回链。
代理模块
说白了就是让专门的大模型进行动态分块,输出结构化边界信息与理由,这个大模型需要专门训练。
适用于高度复杂、长篇、非结构化且混合格式(文本+代码+表格)的文档;

总结