模式引导生成
最简单的prompt 软引导,通过提示词向模型提供明确的指令、具体格式要求,引导模型返回预期结构内容。
|
|
大模型是基于逐令牌(token-by-token)预测器生成内容的,可以通过 temperature 参数设置得较低以减少模型生成响应的随机性,但生成的内容仍具有不确定性,可能会输出不必要的解释文本或生成复杂的嵌套结构时出错。
验证与修复框架
可以对输出内容进行自校验并修正
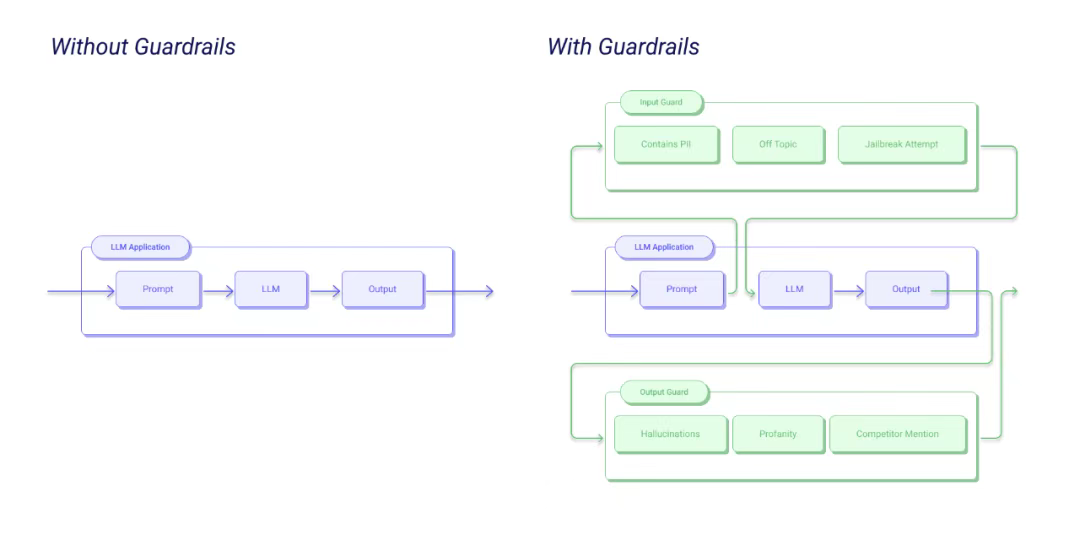
-
先使用 Pydantic 模型或 JsonSchema 等工具,详细定义期望的输出结构、字段类型、以及所需的验证规则和纠正措施。
-
大模型生成输出内容,守卫对象会根据预先定义的结构规范对输出进行自动验证。如果发现输出格式无效、字段缺失、或内容不符合要求,会自动执行纠正措施。
约束解码
从根本上解决大模型的随机性问题,约束解码在模型的生成过程中进行事前干预。其核心技术原理是在大语言模型生成每个令牌(Token)时,通过一个外部预定义的规则集或语法(如有限状态机,FSM)来动态地约束模型的输出空间。
当模型预测下一个令牌的概率分布时,约束解码算法会检查这个分布中哪些令牌是符合预设语法规则的。然后,它将输出空间限制在这些合规的令牌上,并从中选择概率最高的那个作为下一个生成的令牌。
然而对于没有开源的黑盒 LLM,不能深入其内部,就无法在 LLM 输出时就从根本上进行约束解码,于是有了草图引导约束解码方案,核心思想是将黑盒 LLM 的无约束自由文本输出视为一个“草图”,然后再用自己部署的辅助 LLM,根据预定义的规则对黑盒 LLM 输出的这个“草图”进行精炼和修正,在不访问黑盒模型内部机制的情况下实现了约束解码的效果。
监督式微调(SFT)
使用特定领域的高质量有标签数据集训练预训练模型,调整其内部权重,使其永久性地学会生成特定模式输出的技术。
“SFT 高原”现象
-
现象:即使在增加了大规模的有标签数据集之后,模型的性能提升也微乎其微,存在瓶颈无法突破。
-
原因:SFT 本质上是一种模式记忆和泛化。对于需要复杂推理、逻辑链或涉及组合爆炸的任务,仅仅依靠增加数据量是无法让模型掌握其内在逻辑,也就是说纯书呆子,不会举一反三,碰到没见过的新的复杂结构就不行了。
强化学习优化
一句话“有进步就有奖励”,突破了 SFT 高原,与 SFT 单纯依赖静态有标签数据不同,强化学习(RL)通过奖励机制对模型生成结构化输出的正确性进行细粒度、动态的反馈,RL 允许模型通过试错来学习,即使某个输出不完美,只要它比之前的尝试更接近目标,就能获得正向奖励。
总结:接口化能力
说白了就是 MCP 的函数调用,把大模型能力封装成接口,直接调接口返回指定格式的内容,比如返回一个对象,他有各种属性,极大降低开发者实现结构化输出的门槛,也方便对接、解析各种接口。