引言
只做了 Java 后端,想开发一个类似 kimi 的聊天网站,引入多个大模型(文生图模型、图生文模型、文本模型、内嵌模型),支持图生文、文生图、RAG、联网搜索、深度思考。
踩坑
- thinking 模式下仅支持流式输出,意味着需要使用 streamChatModel,如果使用 chatModel 就算开启了 enableThinking、support-incremental-output 也无用.
报错:com.alibaba.dashscope.exception.ApiException: {“statusCode”:400,“message”:"<400> InternalError.Algo.InvalidParameter: The incremental_output parameter must be "true" when enable_thinking is true",“code”:“InvalidParameter”,“isJson”:true}

1
2
3
4
5
6
7
8
9
|
public String chatStr1(String msg) {
AiServices<AiManualService> aiManualService = AiServices.builder(
AiManualService.class)
.chatMemoryProvider(chatMemoryProvider)
.tools(textGenerateImageTool,imageGenerateTextTool)
.chatModel(chatModel)
.streamingChatModel(streamingChatModel);
return aiManualService.build().chatStr1(msg);
}
|
环境依赖
开发环境
JDK21、Postgresql、Redis、通义系列大模型
核心 pom 文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
|
<dependencies>
<!-- searXNG 联网搜索 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-web-search-engine-searxng</artifactId>
<version>1.1.0-beta7</version>
</dependency>
<!-- langchain4j-community-dashscope-spring-boot-starter仅能同时配置一个chatModel和一个streamChatModel,不能同时配置多个,不方便-->
<!-- <dependency>-->
<!-- <groupId>dev.langchain4j</groupId>-->
<!-- <artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>-->
<!-- <version>1.1.0-beta7</version>-->
<!-- </dependency>-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope</artifactId>
<version>1.1.0-beta7</version>
</dependency>
<!-- 基于redis的embeddingStore -->
<!-- <dependency>-->
<!-- <groupId>dev.langchain4j</groupId>-->
<!-- <artifactId>langchain4j-community-redis</artifactId>-->
<!-- </dependency>-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-mcp</artifactId>
<version>1.1.0-beta7</version>
</dependency>
<!-- 文档解析器 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-tika</artifactId>
<version>1.1.0-beta7</version>
</dependency>
<!-- flux流式输出 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.1.0-beta7</version>
</dependency>
<!-- @AiService注解-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>
<!-- 支持结构化输出 -->
<dependency>
<groupId>com.github.victools</groupId>
<artifactId>jsonschema-generator</artifactId>
<version>4.38.0</version>
</dependency>
<!-- 支持文件会话记忆持久化的序列化 -->
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.6.2</version>
</dependency>
<!-- pg vector存储 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pgvector</artifactId>
<version>1.1.0-beta7</version>
</dependency>
<!-- 整合 postgresql -->
<!-- <dependency>-->
<!-- <groupId>org.postgresql</groupId>-->
<!-- <artifactId>postgresql</artifactId>-->
<!-- </dependency>-->
<!-- <dependency>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-starter-jdbc</artifactId>-->
<!-- </dependency>-->
<!-- jsoup HTML 解析库 -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.19.1</version>
</dependency>
<!-- PDF 生成库 -->
<!-- https://mvnrepository.com/artifact/com.itextpdf/itext-core -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext-core</artifactId>
<version>9.1.0</version>
<type>pom</type>
</dependency>
<!-- https://mvnrepository.com/artifact/com.itextpdf/font-asian -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>font-asian</artifactId>
<version>9.1.0</version>
<scope>test</scope>
</dependency>
</dependencies>
|
核心 yml 配置
这个 langchain4j.community.dashscope 前缀是参考 langchain4j-starter 的,实际随便写,为什么不用 langchain4j-starter 呢,上面的 pom 文件提到了,langchain4j-starter 的 yml 配置仅能引入一个 chatModel、streamingModel,而我要引入文本模型、图生文模型、文生图模型,所以 langchain4j-starter 是不符合我们的需求的,因此只能自己写 yml 配置,自己写配置类读取,然后生成 model 的 bean return 出去,后面会提到具体代码,那么 yml 如下,注意,以下所有配置都要自己编码读取!!不是 starter 提供的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
langchain4j:
community:
dashscope:
text-model:
model-name: qwen-plus
api-key: ${DASHSCOPE_AI_KEY}
image-generate-text-model:
model-name: qwen-vl-plus
api-key: ${DASHSCOPE_AI_KEY}
text-generate-image-model:
model-name: wanx2.1-t2i-plus
api-key: ${DASHSCOPE_AI_KEY}
embed-model:
model-name: text-embedding-v4
api-key: ${DASHSCOPE_AI_KEY}
# 向量存储数据源配置
datasource:
pg:
host: 60.205.7.10
port: 5432
database: ai_talk
username: postgres
password: qingqiugeek
table: vector_store
dimension: 1536
# searXNG联网搜索
searxng:
url: http://60.205.7.10:8888
timeout: 60
# contentRetriever 配置
content-retriever:
# 最多 xxx 个检索结果
max-Results: 6
# 过滤掉分数小于 xxx 的结果
min-score: 0.5
# 会话记忆配置
chat-memory:
# 聊天窗口最多存储消息数量
max-messages: 3
# 最多存储会话token数量
max-tokens: 10000
|
${}这种写法是读取的 idea 环境变量,避免把 key 明文写在 yml 配置
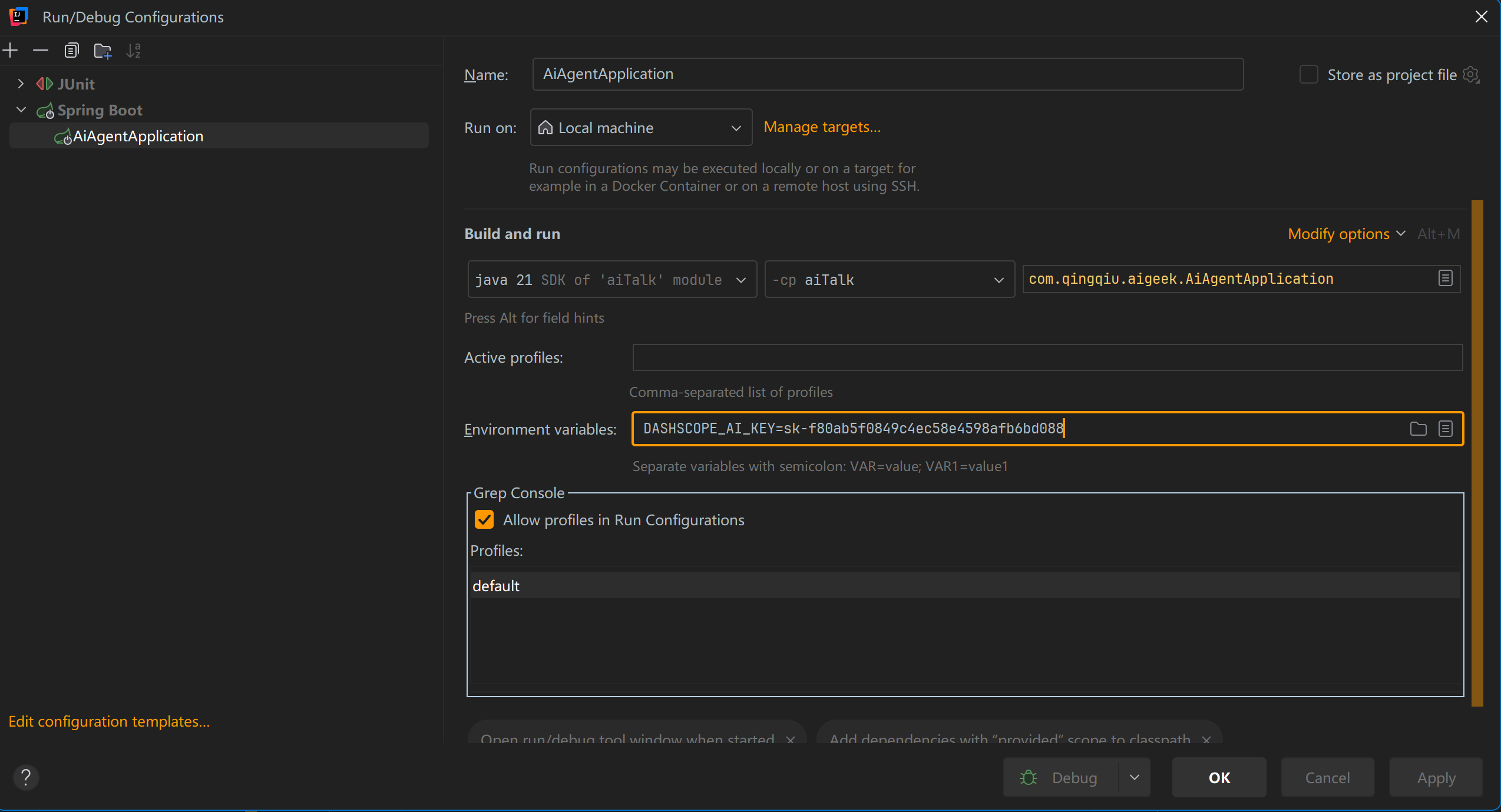
读取 yml 配置
该配置类读取 yml 的模型配置,然后就可以在其他地方注入 QwenModelConfig 直接使用了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
@ConfigurationProperties(prefix = "langchain4j.community.dashscope")
@Configuration
@Data
public class QwenModelConfig {
private TextGenerateImageModel textGenerateImageModel;
private ImageGenerateTextModel imageGenerateTextModel;
private EmbedModel embedModel;
private TextModel textModel;
@Data
public static class TextModel{
private String modelName;
private String apiKey;
}
@Data
public static class ImageGenerateTextModel{
private String modelName;
private String apiKey;
}
@Data
public static class TextGenerateImageModel{
private String modelName;
private String apiKey;
}
@Data
public static class EmbedModel{
private String modelName;
private String apiKey;
}
}
|
生成各种 model 的 bean
注入 QwenModelConfig 开始组装各种 model bean,但是注意,为了让用户自行决定是否启用深度思考、联网搜索、RAG 这些功能,我们不能把 model 的所有配置直接写死,而是仅写死一些通用的配置(chatModelListener),return 出去一个半成品的 model builder,再根据用户请求把半成品 model 配置成成品 model。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
|
@Configuration
@Data
public class QianWenChatModel {
@Resource
private ChatModelListener chatModelListener;
@Resource
private QwenModelConfig qwenModelConfig;
/*
* 普通文本模型 chatModel
* 固定写死enableThinking和enableSearch,选择权不在用户,用户AiAutoService
* */
@Bean
public QwenChatModel textQwenChatModel() {
SearchOptions searchOptions = SearchOptions.builder()
// 返回结果里是否带搜索来源
.enableSource(true)
// 是否开启上标引用
.enableCitation(true)
// 是否强制触发搜索
.forcedSearch(false)
.build();
QwenChatRequestParameters parameters = QwenChatRequestParameters.builder()
.enableSearch(true)
.searchOptions(searchOptions)
.build();
return QwenChatModel.builder()
.apiKey(qwenModelConfig.getTextModel().getApiKey())
.modelName(qwenModelConfig.getTextModel().getModelName())
.enableSearch(true)
.defaultRequestParameters(parameters)
.listeners(List.of(chatModelListener))
.build();
}
/*
* 流式文本模型 streamingChatModel
* 固定写死enableThinking和enableSearch,选择权不在用户,用户AiAutoService
* */
@Bean
public QwenStreamingChatModel textQwenStreamingChatModel() {
SearchOptions searchOptions = SearchOptions.builder()
// 返回结果里是否带搜索来源
.enableSource(true)
// 是否开启上标引用
.enableCitation(true)
// 是否强制触发搜索
.forcedSearch(false)
.build();
QwenChatRequestParameters parameters = QwenChatRequestParameters.builder()
.enableThinking(true)
.isMultimodalModel(true)
.enableSearch(true)
.searchOptions(searchOptions)
.build();
return QwenStreamingChatModel.builder()
.apiKey(qwenModelConfig.getTextModel().getApiKey())
.modelName(qwenModelConfig.getEmbedModel().getModelName())
.isMultimodalModel(true)
.enableSearch(true)
.defaultRequestParameters(parameters)
.listeners(List.of(chatModelListener))
.build();
}
/*
* 文生图模型参数配置
* */
@Bean
public ImageSynthesisParamBuilder textGenerateImageQwenChatModel() {
return ImageSynthesisParam.builder()
.apiKey(qwenModelConfig.getTextGenerateImageModel().getApiKey())
.model(qwenModelConfig.getTextGenerateImageModel().getModelName())
.prompt("")
.negativePrompt("")
.n(1)
.size("1024*1024");
}
/*
* 图生文模型参数配置
* */
@Bean
public MultiModalConversationParamBuilder imageGenerateTextQwenChatModel() {
return MultiModalConversationParam.builder()
.apiKey(qwenModelConfig.getImageGenerateTextModel().getApiKey())
.model(qwenModelConfig.getImageGenerateTextModel().getModelName());
}
/*
* 通用 QwenChatModelBuilder,用于AiManualServiceImpl
* 把「不会变」的公共配置(apiKey、modelName、listener)提前注入到 Builder 里,是否开启思考、联网搜索则根据用户的参数进行填写。
* */
@Bean
public QwenChatModelBuilder textQwenChatModelBuilder() {
return QwenChatModel.builder()
.apiKey(qwenModelConfig.getTextModel().getApiKey())
.modelName(qwenModelConfig.getTextModel().getModelName())
.listeners(List.of(chatModelListener));
}
/**
* 通用 QwenStreamingChatModelBuilder,用于AiManualServiceImpl
* 把「不会变」的公共配置(apiKey、modelName、listener)提前注入到 Builder 里,是否开启联网搜索则根据用户的参数进行填写。
*/
@Bean
public QwenStreamingChatModelBuilder textQwenStreamingChatModelBuilder() {
return QwenStreamingChatModel.builder()
.apiKey(qwenModelConfig.getTextModel().getApiKey())
.modelName(qwenModelConfig.getTextModel().getModelName())
.listeners(List.of(chatModelListener));
}
/**
* 嵌入向量模型
*/
@Bean
public EmbeddingModel embeddingModel() {
return QwenEmbeddingModel.builder()
.apiKey(qwenModelConfig.getEmbedModel().getApiKey())
.modelName(qwenModelConfig.getEmbedModel().getModelName())
.build();
}
}
|
ChatModelListener
ChatModelListener,获取 ChatModel 的调用信息,打印日志,建议给每个 model bean 都用上
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
@Configuration
@Slf4j
public class ChatModelListenerConfig {
@Bean
ChatModelListener chatModelListener() {
return new ChatModelListener() {
@Override
public void onRequest(ChatModelRequestContext requestContext) {
log.info("ip: {},onRequest: {}",IPUtil.getIpAddr(), requestContext.chatRequest());
}
@Override
public void onResponse(ChatModelResponseContext responseContext) {
log.info("onResponse: {}", responseContext.chatResponse());
}
@Override
public void onError(ChatModelErrorContext errorContext) {
log.info("onError: {}", errorContext.error().getMessage());
}
};
}
}
|
向量存储 EmbeddingStore
我选择存储在 postgresql,postgresql 有一个数据库插件 pgvector,给指定的数据库安装后,这个数据库就支持向量存储了
读取配置 EmbeddingStoreConfig
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
@ConfigurationProperties(prefix = "datasource.pg")
@Configuration
@Data
public class EmbeddingStoreConfig {
private String host;
private Integer port;
private String username;
private String password;
private String database;
private String table;
private Integer dimension;
}
|
配置 EmbeddingStore
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
@Configuration
@Data
public class EmbeddingStore {
@Resource
EmbeddingStoreConfig embeddingStoreConfig;
@Bean
@Qualifier("pgVectorEmbeddingStore")
public PgVectorEmbeddingStore pgVectorEmbeddingStore() {
return PgVectorEmbeddingStore
.builder()
.host(embeddingStoreConfig.getHost())
.port(embeddingStoreConfig.getPort())
.database(embeddingStoreConfig.getDatabase())
.user(embeddingStoreConfig.getUsername())
.password(embeddingStoreConfig.getPassword())
.table(embeddingStoreConfig.getTable())
.dimension(embeddingStoreConfig.getDimension())
.metadataStorageConfig(DefaultMetadataStorageConfig.defaultConfig())
.build();
}
@Bean
@Qualifier("inMemoryEmbeddingStore")
public InMemoryEmbeddingStore<TextSegment> inMemoryEmbeddingStore() {
return new InMemoryEmbeddingStore<>();
}
}
|
内容检索器 ContentRetriever
内容检索器顾名思义就是检索内容的工具,要给它配置检索的数据源 store、嵌入模型 model、检索 result、分数 score,我配置了三个,分别基于内存 memory、联网搜索 searXNG、向量数据库 pgvector,searXNG 是一个开源的搜索工具,自己部署后可以调用搜索 API 实现联网搜索。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
@Configuration
@Data
public class ContentRetrievers {
@Resource
SearXNGConfig searXNGConfig;
@Resource
RagConfig ragConfig;
@Resource
private EmbeddingModel embeddingModel;
@Autowired
@Qualifier("pgVectorEmbeddingStore")
PgVectorEmbeddingStore pgVectorEmbeddingStore;
@Autowired
@Qualifier("inMemoryEmbeddingStore")
InMemoryEmbeddingStore<TextSegment> inMemoryEmbeddingStore;
// @Resource
// DocumentParser apacheTikaDocumentParser;
// @Resource
// DocumentSplitter documentSplitter;
/*
* 基于pgVectorEmbeddingStore的 rag
* */
@Bean
@Qualifier("pgVectorContentRetriever")
public EmbeddingStoreContentRetriever pgVectorContentRetriever() {
// 自定义内容查询器 !!!注意,数据预处理和查询处理的embeddingStore要相同
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(pgVectorEmbeddingStore)
.embeddingModel(embeddingModel)
.maxResults(ragConfig.getMaxResults())
.minScore(ragConfig.getMinScore())
.build();
}
/*
* 基于内存的 rag
* */
@Bean
@Qualifier("inMemoryContentRetriever")
public EmbeddingStoreContentRetriever inMemoryContentRetriever() {
// 自定义内容查询器 !!!注意,数据预处理和查询处理的embeddingStore要相同
return EmbeddingStoreContentRetriever.builder()
.embeddingStore(inMemoryEmbeddingStore)
.embeddingModel(embeddingModel)
.maxResults(ragConfig.getMaxResults())
.minScore(ragConfig.getMinScore())
.build();
}
/*
* 基于联网搜索的 RAG
* */
@Bean
public WebSearchContentRetriever webSearchContentRetriever(){
//指定启用和禁用的搜索引擎
Map<String, Object> searXNGParams = getSearXNGParams();
//--联网搜索引擎,这里使用自建的searxng,官方文档:github.com/searxng/searxng
WebSearchEngine webSearchEngine =
SearXNGWebSearchEngine.builder().optionalParams(searXNGParams)
.duration(Duration.ofSeconds(searXNGConfig.getTimeout()))
.logRequests(true).logResponses(true).baseUrl(searXNGConfig.getUrl()).build();
return WebSearchContentRetriever.builder()
.webSearchEngine(webSearchEngine)
.maxResults(ragConfig.getMaxResults())
.build();
}
}
|
RetrievalAugmentor
检索增强,它就是 RAG 种的 RA,我们前面提供了内容检索器 ContentRetriever。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
@Configuration
public class RetrievalAugmentors {
/**
* 支不持联网搜索的
* @return
*/
@Bean
@Qualifier("disableWebSearchQueryRouterRetrievalAugmentor")
public DefaultRetrievalAugmentor disableWebSearchQueryRouterRetrievalAugmentor() {
SwitchQueryRouter switchQueryRouter = new SwitchQueryRouter(false);
//--检索query增强器,通过从不同的数据源查询检索,给chat返回增强后的对话信息
return DefaultRetrievalAugmentor.builder()
.queryRouter(switchQueryRouter)
.build();
}
/**
* 支持联网搜索的
* @return
*/
@Bean
@Qualifier("enableWebSearchQueryRouterRetrievalAugmentor")
public DefaultRetrievalAugmentor enableWebSearchQueryRouterRetrievalAugmentor() {
SwitchQueryRouter switchQueryRouter = new SwitchQueryRouter(true);
//--检索query增强器,通过从不同的数据源查询检索,给chat返回增强后的对话信息
return DefaultRetrievalAugmentor.builder()
.queryRouter(switchQueryRouter)
.build();
}
/**
* DefaultRetrievalAugmentorBuilder暴露出去,根据用户是否联网搜索传入switchQueryRouter,进而构建defaultQueryRouterRetrievalAugmentor
* 暴漏builder优点是可以任意组合 Retriever。
* 此时先不考虑该方案,选的方案是 直接暴露出去两个bean DefaultRetrievalAugmentor,一个支持联网搜索,一个不支持联网搜索
* @return
*/
// @Bean
public DefaultRetrievalAugmentorBuilder defaultQueryRouterRetrievalAugmentorBuilder() {
//--检索query增强器,通过从不同的数据源查询检索,给chat返回增强后的对话信息
return DefaultRetrievalAugmentor.builder();
}
}
|
查询路由选择器 QueryRouter
我们给 Model 配置了 RetrievalAugmentor 用于检索增强,但是 Model 如何知道什么时候检索,从哪里检索(内存、redis、向量数据库),什么时候不检索呢,因此还需要一个智能路由选择器,然后将其配置给 RetrievalAugmentor。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
public class SwitchQueryRouter implements QueryRouter {
/**
* contentRetrievers包含定义的所有的contentRetriever
*/
@Resource
private Collection<ContentRetriever> contentRetrievers;
private final Boolean enableSearch;
public SwitchQueryRouter(Boolean enableSearch) {
this.enableSearch = enableSearch;
}
@Override
public Collection<ContentRetriever> route(Query query) {
// 用户的文本,目前只是根据enableSearch实现了简单的路由规则,要实现更复杂的,可以根据用户的文本内容筛选过滤contentRetriever,如下:
// 1.
// String text = query.text();
// query.metadata().chatMemoryId()
// String role = userService.roleOf(userId); // 权限逻辑路由规则
// return List.of(retrievers.get(role));
// 2.
// 如果包含“最新”或“今天”,启用 Web 搜索
// boolean needsWebSearch = text.contains("最新") || text.contains("今天");
// 3.
// LanguageModelQueryRouter router = LanguageModelQueryRouter.builder().
// .chatModel()
// .fallbackStrategy()
// .retrieverToDescription(List.of(Map.of("name1",contentRetriever1,"name2",contentRetriever2)))
// .build()
if (!enableSearch) {
//开关关闭,不走联网检索
return contentRetrievers.stream().filter(contentRetriever -> !(contentRetriever instanceof WebSearchContentRetriever)).toList();
}
return contentRetrievers;
}
}
|
聊天记忆提供器 ChatMemoryProvider
它和 ContentRetriever 挺像的,都是从某个地方拿数据并提供给其他组件使用,我实现了基于 redis、内存、文件三种方式。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
@Data
@ConfigurationProperties(prefix = "chat-memory")
@Configuration
public class ChatMemoryProvider {
private Integer maxMessages;
private Integer maxTokens;
/*
* 基于内存的持久记忆,是框架自动提供的,不需要手动实现
* */
@Bean
dev.langchain4j.memory.chat.ChatMemoryProvider inMemoryStoreChatMemoryProvider(){
return sessionId -> MessageWindowChatMemory.builder().chatMemoryStore(new InMemoryChatMemoryStore()).maxMessages(maxMessages).id(sessionId).build();
}
/*
* 基于redis的持久记忆,要手动实现
* */
@Bean
dev.langchain4j.memory.chat.ChatMemoryProvider redisStoreChatMemoryProvider(){
return sessionId -> MessageWindowChatMemory.builder().chatMemoryStore(new RedisMemoryStore()).maxMessages(maxMessages).id(sessionId).build();
}
/*
* 基于文件的持久记忆,要手动实现
* */
@Bean
dev.langchain4j.memory.chat.ChatMemoryProvider fileStoreChatMemoryProvider(){
return sessionId -> MessageWindowChatMemory.builder().chatMemoryStore(new FileMemoryStore()).maxMessages(maxMessages).id(sessionId).build();
}
}
|
ChatMemory
ChatMemory 是一个接口,有两种具体实现,一个基于 MessageWindow 一个基于 TokenWindow,我用的 MessageWindow
RedisMemoryStore
要控制每个会话的聊天长度,会话长度到达阈值,提示用户开启新会话
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
public class RedisMemoryStore implements ChatMemoryStore {
@Resource
private StringRedisTemplate redisTemplate;
private final ObjectMapper objectMapper = new ObjectMapper();
/* ---------- 核心接口 ---------- */
@Override
public List<ChatMessage> getMessages(Object memoryId) {
String key = CHAT_HISTORY + memoryId;
List<String> jsonList = redisTemplate.opsForList().range(key, 0, -1);
if (jsonList == null || jsonList.isEmpty()) {
return List.of();
}
return jsonList.stream()
.map(this::toChatMessage)
.collect(Collectors.toList());
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
String key = CHAT_HISTORY + memoryId;
// 清空旧数据
redisTemplate.delete(key);
if (messages.isEmpty())
return;
// 批量追加新数据
List<String> jsons = messages.stream()
.map(this::toJson)
.collect(Collectors.toList());
redisTemplate.opsForList().rightPushAll(key, jsons);
//设置有效期
// redisTemplate.expire(key, CHAT_HISTORY_TTL, TimeUnit.DAYS);
}
@Override
public void deleteMessages(Object memoryId) {
redisTemplate.delete(CHAT_HISTORY + memoryId);
}
/* ---------- 序列化/反序列化 ---------- */
private String toJson(ChatMessage msg) {
try {
return objectMapper.writeValueAsString(msg);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
private ChatMessage toChatMessage(String json) {
try {
return objectMapper.readValue(json, ChatMessage.class);
} catch (JsonProcessingException e) {
throw new RuntimeException(e);
}
}
}
|
FileMemoryStore
基于文件存储选用 kryo 序列化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
|
@Component
public class FileMemoryStore implements ChatMemoryStore {
private static final Kryo kryo = new Kryo();
static {
kryo.setRegistrationRequired(false);
// 设置实例化策略
kryo.setInstantiatorStrategy(new StdInstantiatorStrategy());
}
// 构造对象时,指定文件保存目录
public FileMemoryStore() {
File baseDir = new File(FILE_SAVE_DIR);
if (!baseDir.exists()) {
baseDir.mkdirs();
}
}
@Override
public void deleteMessages(Object memoryId) {
File file = getConversationFile((String)memoryId);
if (file.exists()) {
file.delete();
}
}
@Override
public List<ChatMessage> getMessages(Object memoryId) {
return getOrCreateConversation((String)memoryId);
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
List<ChatMessage> conversationHistory = getOrCreateConversation((String)memoryId);
conversationHistory.addAll(messages);
saveConversation((String)memoryId, conversationHistory);
}
private List<ChatMessage> getOrCreateConversation(String memoryId) {
File file = getConversationFile(memoryId);
List<ChatMessage> messages = new ArrayList<>();
if (file.exists()) {
try (Input input = new Input(new FileInputStream(file))) {
messages = kryo.readObject(input, ArrayList.class);
} catch (IOException e) {
e.printStackTrace();
}
}
return messages;
}
private void saveConversation(String memoryId, List<ChatMessage> messages) {
File file = getConversationFile(memoryId);
try (Output output = new Output(new FileOutputStream(file))) {
kryo.writeObject(output, messages);
} catch (IOException e) {
e.printStackTrace();
}
}
private File getConversationFile(String memoryId) {
return new File(FILE_SAVE_DIR, memoryId + ".kryo");
}
}
|
护轨 Guardrails
类似大模型的请求、响应拦截器,可以对输入输出结果做检测,比如我的敏感词检测,加载文件中的敏感词作为输入护轨配置给 aiService,检测用户输入是否包含敏感词,若包含则拦截该输入并提示用户。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
@Slf4j
@Component
public class SensitiveWordsInputGuardrail implements InputGuardrail {
private static final Set<String> sensitiveWords;
// 静态初始化块,用于加载敏感词
static {
sensitiveWords = loadSensitiveWords();
log.info("敏感词加载成功!");
}
/**
* 检测用户输入是否安全
*/
@Override
public InputGuardrailResult validate(UserMessage userMessage) {
// 获取用户输入并转换为小写以确保大小写不敏感
String inputText = userMessage.singleText().toLowerCase();
// 使用正则表达式分割输入文本为单词
String[] words = inputText.split("\\W+");
// 遍历所有单词,检查是否存在敏感词
for (String word : words) {
if (sensitiveWords.contains(word)) {
return fatal("IP: " + getIpAddr() + "Sensitive word detected: "+ word);
}
}
return success();
}
/**
* 从资源文件中加载敏感词
*/
private static Set<String> loadSensitiveWords() {
Set<String> words = new HashSet<>();
URL directoryUrl = SensitiveWordsInputGuardrail.class.getClassLoader()
.getResource("sensitiveLexicon");
if (directoryUrl != null) {
// 如果资源在文件系统中
if (directoryUrl.getProtocol().equals("file")) {
File directory = null;
try {
directory = new File(directoryUrl.toURI());
} catch (URISyntaxException e) {
throw new RuntimeException(e);
}
File[] files = directory.listFiles((dir, name) -> name.endsWith(".txt"));
if (files != null) {
for (File file : files) {
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(new FileInputStream(file), StandardCharsets.UTF_8))) {
String line;
while (true) {
if ((line = reader.readLine()) == null) {
break;
}
words.add(line.trim().toLowerCase());
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
}
}
return words;
}
}
|
重头戏 AiService
注意,每个用户的需求、上下文是不同的,如果要支持多用户同时并发使用,那么肯定要为每个用户的请求单独配置 AiService,所以 AiService 是有状态的 bean,不是类似 MVC 中的通用无状态 Service。
注意,除了可以给 aiService 配置 RetrievalAugmentor 外,还可以配置 ContentRetriever,两者区别是,RetrievalAugmentor 要配置查询路由 QueryRouter,而查询路由 QueryRouter 则包含了多个内容检索器 ContentRetriever,可以从多个数据源检索增强,如果只想从 1 个 ContentRetriever 中检索,则只需配置.contentRetriever()即可,无需.retrievalAugmentor()了。
为了练习测试,我写了很多个方法,基于 AiManualService.class 构建(后面有代码),做不同的配置,包含流式、非流式响应。
Manual 的意思是手动,因为我是手动构建 AiService 的,这样才能满足我的多样化需求,后面还有自动的 AiService。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
|
@Component
public class AiManualApp {
@Autowired
@Qualifier("enableWebSearchQueryRouterRetrievalAugmentor")
private RetrievalAugmentor enableWebSearchQueryRouterRetrievalAugmentor;
@Autowired
@Qualifier("disableWebSearchQueryRouterRetrievalAugmentor")
private RetrievalAugmentor disableWebSearchQueryRouterRetrievalAugmentor;
@Resource(name = "inMemoryStoreChatMemoryProvider")
ChatMemoryProvider chatMemoryProvider;
@Resource
QwenStreamingChatModelFactory qwenStreamingChatModelFactory;
@Resource
QwenChatModel chatModel;
@Resource
ImageGenerateTextTool imageGenerateTextTool;
@Resource
TextGenerateImageTool textGenerateImageTool;
@Autowired
private StreamingChatModel streamingChatModel;
/**
* 联网搜索时获取引用
*/
public List<Content> getResource(String topic){
return null;
}
/**
* 返回的string,因此调用chatModel
* @param userMessage
* @return
*/
public String chatStr(UserMessageDTO userMessage) {
AiManualService aiManualService = AiServices.builder(AiManualService.class)
.chatMemoryProvider(chatMemoryProvider)
.chatModel(chatModel)
.retrievalAugmentor(disableWebSearchQueryRouterRetrievalAugmentor)
.build();
return aiManualService.chatStr(userMessage.getSessionId(),userMessage.getUserMessage());
}
public Result<List<String>> chatResult(UserMessageDTO userMessage) {
AiManualService aiManualService = AiServices.builder(AiManualService.class)
.chatMemoryProvider(chatMemoryProvider)
.chatModel(chatModel)
.retrievalAugmentor(disableWebSearchQueryRouterRetrievalAugmentor)
.build();
return aiManualService.chatResult(userMessage.getSessionId(),userMessage.getUserMessage());
}
public Flux<ServerSentEvent<String>> chatTokenStream(UserMessageDTO userMessage) {
QwenStreamingChatModel qwenStreamingChatModel = qwenStreamingChatModelFactory.createQwenStreamingChatModel(
userMessage.getEnableSearch(), userMessage.getEnableThinking());
AiServices<AiManualService> aiManualService = AiServices.builder(
AiManualService.class)
.chatMemoryProvider(chatMemoryProvider)
.streamingChatModel(qwenStreamingChatModel);
if(userMessage.getEnableSearch()){
aiManualService.retrievalAugmentor(enableWebSearchQueryRouterRetrievalAugmentor);
}else {
aiManualService.retrievalAugmentor(disableWebSearchQueryRouterRetrievalAugmentor);
}
TokenStream tokenStream = aiManualService.build().chatTokenStream(userMessage.getSessionId(),
userMessage.getUserMessage());
Sinks.Many<ServerSentEvent<String>> sink = Sinks.many().unicast().onBackpressureBuffer();
//rag回调
tokenStream.onRetrieved(contents ->
//前端可监听Retrieved时间,展示命中的文件
sink.tryEmitNext(ServerSentEvent.builder(toJson(convertToRecord(contents))).event("Retrieved").build()));
//消息片段回调
tokenStream.onPartialResponse(partialResponse -> sink.tryEmitNext(ServerSentEvent.builder(partialResponse).event("AiMessage").build()));
//错误回调
tokenStream.onError(sink::tryEmitError);
//结束回调
tokenStream.onCompleteResponse(aiMessageResponse -> sink.tryEmitComplete());
tokenStream.start();
return sink.asFlux();
}
public Flux<String> chatFlux(UserMessageDTO userMessage) {
QwenStreamingChatModel qwenStreamingChatModel = qwenStreamingChatModelFactory.createQwenStreamingChatModel(
userMessage.getEnableSearch(), userMessage.getEnableThinking());
AiServices<AiManualService> aiManualService = AiServices.builder(
AiManualService.class)
.chatMemoryProvider(chatMemoryProvider)
.tools(textGenerateImageTool,imageGenerateTextTool)
.streamingChatModel(qwenStreamingChatModel);
if(userMessage.getEnableSearch()){
aiManualService.retrievalAugmentor(enableWebSearchQueryRouterRetrievalAugmentor);
}else {
aiManualService.retrievalAugmentor(disableWebSearchQueryRouterRetrievalAugmentor);
}
return aiManualService.build().chatFlux(userMessage.getSessionId(),userMessage.getUserMessage());
}
public String chatStr1(String msg) {
AiServices<AiManualService> aiManualService = AiServices.builder(
AiManualService.class)
.chatMemoryProvider(chatMemoryProvider)
.tools(textGenerateImageTool,imageGenerateTextTool)
.chatModel(chatModel)
.streamingChatModel(streamingChatModel);
return aiManualService.build().chatStr1(msg);
}
public Flux<String> chatFlux1(String msg) {
AiServices<AiManualService> aiManualService = AiServices.builder(
AiManualService.class)
.chatMemoryProvider(chatMemoryProvider)
.tools(textGenerateImageTool,imageGenerateTextTool)
.chatModel(chatModel)
.streamingChatModel(streamingChatModel);
return aiManualService.build().chatFlux1(msg);
}
public Flux<String> chatResponse(UserMessageDTO userMessage) {
QwenStreamingChatModel qwenStreamingChatModel = qwenStreamingChatModelFactory.createQwenStreamingChatModel(
userMessage.getEnableSearch(), userMessage.getEnableThinking());
AiServices<AiManualService> aiManualService = AiServices.builder(
AiManualService.class)
.chatMemoryProvider(chatMemoryProvider)
.streamingChatModel(qwenStreamingChatModel);
if(userMessage.getEnableSearch()){
aiManualService.retrievalAugmentor(enableWebSearchQueryRouterRetrievalAugmentor);
}else {
aiManualService.retrievalAugmentor(disableWebSearchQueryRouterRetrievalAugmentor);
}
return aiManualService.build().chatFlux(userMessage.getSessionId(),userMessage.getUserMessage());
}
}
|
AiManualService
这里配置敏感词检测的输入护轨,同时可以给方法定义不同的角色
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
@InputGuardrails(SensitiveWordsInputGuardrail.class)
public interface AiManualService {
String chatStr(@MemoryId String sessionId,@UserMessage String message);
/*
* aiService服务自动返回Result<List<String>>
* */
@SystemMessage("你是健身专家,仅回答健身领域知识")
Result<List<String>> chatResult(@MemoryId String sessionId, String message);
/*
* 返回流式的
* */
@SystemMessage(fromResource = "prompt/prompt1.txt")
TokenStream chatTokenStream(@MemoryId String sessionId, String message);
/**
* 流式调用
*/
Flux<String> chatFlux(@MemoryId String sessionId, String message);
Flux<String> chatFlux1(String message);
String chatStr1(String message);
/**
* chatResponse
*/
ChatResponse chatResponse(@MemoryId String sessionId, String message);
}
|
AiAutoService
所谓自动就是仅需一个@AiService 注解就能生成 AiService,不需要用 AiServices.builder()构建,简单但是不够灵活。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
@InputGuardrails(value = SensitiveWordsInputGuardrail.class)
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT
, streamingChatModel = "textQwenStreamingChatModel"
, chatModel = "textQwenChatModel"
, retrievalAugmentor = "disableWebSearchQueryRouterRetrievalAugmentor"
, chatMemoryProvider = "inMemoryStoreChatMemoryProvider"
, tools = {"testTool", "scrapeWebPageTool","resourceDownloadTool"})
public interface AiAutoService {
/**
* @SystemMessage 设定角色,塑造AI助手的专业身份,明确助手的能力范围,@SystemMessage 的内容将在后台转换为 SystemMessage 对象,并与 UserMessage 一起发送给大语
* 言模型(LLM)。SystemMessaged的内容只会发给大模型一次,如果修改了SystemMessage的内容,新的SystemMessage会被发送给大模型,之前的聊天记忆会失效。
* @param userMessage
* @return
*/
@SystemMessage("你是一个顶级IT开发专家,仅回答IT领域的知识")
String chatStr(String userMessage);
ChatResponse chatResponse(String userMessage);
@SystemMessage("你是健身专家,仅回答健身领域知识")
Result<List<String>> chatResult(String userMessage);
/**
* 聊天流式输出
* @param sessionId 会话id,通过@MemoryId指定
* @param role 设定角色,通过@V注解替换掉system-message.txt中的role变量
* @param question 原始问题,通过@V注解替换掉user-message.txt中的question变量
* @param extraInfo 额外信息
* @return
*/
@SystemMessage(fromResource = "prompt/system-message.txt")
@UserMessage(fromResource = "prompt/user-message.txt")
Flux<String> chatFlux(
@MemoryId String sessionId,
@V("role") String role,
@V("question") String question,
@V("extraInfo") String extraInfo);
@SystemMessage(fromResource = "prompt/system-message.txt")
@UserMessage(fromResource = "prompt/user-message.txt")
TokenStream chatTokenStream(
@MemoryId String sessionId,
@V("role") String role,
@V("question") String question,
@V("extraInfo") String extraInfo);
}
|
我是把图生文、文生图模型的能力开发成了 Tool 工具,配置给文本模型,让文本模型根据用户输入自主决策是否调用。
注意@Tool 注解的参数和方法的入参注释很重要,决定了大模型是否能理解、调用该工具
图生文工具
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
@Slf4j
@Component
public class ImageGenerateTextTool {
@Resource
MultiModalConversationParamBuilder multiModalConversationParamBuilder;
/**
* 解析图片并回答用户问题。
* @param base64Image 图片的 Base64 字符串(不含 data:image 头)
* @param userMessage 用户针对图片提出的问题
* @return 多模态模型给出的文字答案;若失败则返回错误提示
*/
@Tool(value = {
"analyze_image",
"当你需要**理解画、照片等图片内容**或**回答与图片有关的问题**时调用此工具。",
"入参:图片(Base64格式的字符串,必须包含data:image前缀) + 用户的问题;返回:模型生成的文字描述/回答。"
})
public String analyzeImage(
@P(value = "图片的 Base64 字符串,必须包含data:image前缀,例如:data:image/png;base64,xxx...") String base64Image,
@P(value = "用户针对图片提出的问题,例如:描述这张图片") String userMessage) {
if (base64Image == null || base64Image.isBlank()) {
return "图片为空,无法解析!";
}
try {
MultiModalConversation conv = new MultiModalConversation();
MultiModalMessage userMsg = MultiModalMessage.builder()
.role(Role.USER.getValue())
.content(List.of(
Map.of("image", base64Image),
Map.of("text", userMessage)
))
.build();
MultiModalConversationParam param = multiModalConversationParamBuilder.message(userMsg).build();
MultiModalConversationResult result = conv.call(param);
log.info("图生文结果:{}", JsonUtils.toJson(result));
return result.getOutput().getChoices().getFirst().getMessage().getContent()
.stream()
.filter(c -> c.containsKey("text"))
.map(c -> c.get("text").toString())
.findFirst()
.orElse("模型未返回文本内容。");
} catch (Exception e) {
log.error("调用图生文模型失败: ", e);
return "抱歉,解析图片时出现异常:" + e.getMessage();
}
}
}
|
文生图工具
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
@Slf4j
@Component
public class TextGenerateImageTool {
@Resource
private ImageSynthesisParamBuilder iSynthesisParamBuilder;
/**
* 根据用户描述生成图片
*
* @param prompt 用户文本描述,如“画一只可爱的小狗”
* @return 成功返回图片 URL;失败返回错误提示
*/
@Tool(value = {
"generate_image",
"当你需要**根据文字描述生成图片、画等**时调用此工具。",
"入参:用户文字描述;返回:https格式的图片URL,如https://xxxx。"
})
public String generateImage(
@P(value = "用户有关图片的文字描述,例如:一只在草地上奔跑的蔡徐坤") String prompt) {
if (prompt == null || prompt.isBlank()) {
return "描述为空,无法生成图片!";
}
try {
ImageSynthesis conv = new ImageSynthesis();
ImageSynthesisParam param = iSynthesisParamBuilder.prompt(prompt).build();
ImageSynthesisResult result = conv.call(param);
log.info("文生图结果:{}", JsonUtils.toJson(result));
// SUCCEEDED 取第一张图 URL
if ("SUCCEEDED".equalsIgnoreCase(result.getOutput().getTaskStatus())) {
return result.getOutput().getResults()
.getFirst().get("url");
} else {
return "图片生成任务未完成,状态: " + result.getOutput().getTaskStatus();
}
} catch (Exception e) {
log.error("调用文生图模型失败: ", e);
return "抱歉,生成图片时出现异常: " + e.getMessage();
}
}
}
|
Base64 转换工具
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
|
@Configuration
public class Base64Tool {
/** 允许的图片后缀集合,可按需扩展 */
private static final Set<String> IMG_EXT = Set.of(
"png", "jpg", "jpeg", "gif", "bmp", "webp"
);
/**
* 将上传的图片文件转成带 data URI 的 Base64 字符串
* @param image 待转换的图片文件
* @return 形如 data:image/png;base64,xxxxx...
* @throws IOException 读取文件失败
*/
@Tool("Convert an uploaded image file to a data-URI base64 string")
public String imageConvertToBase64(@V("The image file to be converted") MultipartFile image) throws IOException {
if (image == null || image.isEmpty()) {
throw new BusinessException(BusinessExceptionEnum.PARAMS_ERROR.getCode(), BusinessExceptionEnum.PARAMS_ERROR.getMessage());
}
// 1. 取后缀并校验
String original = image.getOriginalFilename();
if (original == null || !original.contains(".")) {
throw new BusinessException(BusinessExceptionEnum.IMAGE_TYPE_ERROR.getCode(), BusinessExceptionEnum.IMAGE_TYPE_ERROR.getMessage());
}
String ext = original.substring(original.lastIndexOf('.') + 1);
if (!IMG_EXT.contains(ext)) {
throw new BusinessException(BusinessExceptionEnum.IMAGE_TYPE_ERROR.getCode(), BusinessExceptionEnum.IMAGE_TYPE_ERROR.getMessage());
}
// 2. 编码
String base64 = Base64.getEncoder().encodeToString(image.getBytes());
// 3. 拼接前缀
return "data:image/" + ext + ";base64," + base64;
}
}
|
网页抓取工具
为了让大模型能理解用户输入的网页链接的内容,写一个网页抓取工具
1
2
3
4
5
6
7
8
9
10
11
12
13
|
@Configuration
public class ScrapeWebPageTool {
@Tool("Scrape the content of a web page")
public String scrapeWebPageTool(@P(value = "URL of the web page to scrape") String url) {
try {
Document document = Jsoup.connect(url).get();
return document.html();
} catch (Exception e) {
return "Error scraping web page: " + e.getMessage();
}
}
}
|
网络资源下载工具
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
@Configuration
public class ResourceDownloadTool {
@Tool("Download resource from a given URL")
public String resourceDownloadTool(@P(value = "URL of the resource to download") String url
, @P(value = "Name of the file to save the downloaded resource") String fileName) {
String fileDir = FILE_SAVE_DIR + "/download";
String filePath = fileDir + "/" + fileName;
try {
// 创建目录
FileUtil.mkdir(fileDir);
// 使用 Hutool 的 downloadFile 方法下载资源
HttpUtil.downloadFile(url, new File(filePath));
return "Resource downloaded successfully to: " + filePath;
} catch (Exception e) {
return "Error downloading resource: " + e.getMessage();
}
}
}
|
PDF 生成工具
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
@Configuration
public class PDFGenerationTool {
@Tool("Generate a PDF file with given content")
public String pDFGeneration(
@P(value = "the filename of pdf")
String fileName,
@P(value = "the fileContent of pdf")
String content) {
String fileDir = FILE_SAVE_DIR + "/pdf";
String filePath = fileDir + "/" + fileName;
try {
// 创建目录
FileUtil.mkdir(fileDir);
// 创建 PdfWriter 和 PdfDocument 对象
try (PdfWriter writer = new PdfWriter(filePath);
PdfDocument pdf = new PdfDocument(writer);
Document document = new Document(pdf)) {
// 自定义字体(需要人工下载字体文件到特定目录)
// String fontPath = Paths.get("src/main/resources/static/fonts/simsun.ttf")
// .toAbsolutePath().toString();
// PdfFont font = PdfFontFactory.createFont(fontPath,
// PdfFontFactory.EmbeddingStrategy.PREFER_EMBEDDED);
// 使用内置中文字体
PdfFont font = PdfFontFactory.createFont("STSongStd-Light", "UniGB-UCS2-H");
document.setFont(font);
// 创建段落
Paragraph paragraph = new Paragraph(content);
// 添加段落并关闭文档
document.add(paragraph);
}
return "PDF generated successfully to: " + filePath;
} catch (IOException e) {
return "Error generating PDF: " + e.getMessage();
}
}
}
|
文件读写工具
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
@Configuration
public class FileOperationTool {
private final String FILE_DIR = FILE_SAVE_DIR + "/file";
@Tool(name = "ReadFileTool" , value = "Read content from a file")
public String readFile(@P(value = "Name of a file to read") String fileName) {
String filePath = FILE_DIR + "/" + fileName;
try {
return FileUtil.readUtf8String(filePath);
} catch (Exception e) {
return "Error reading file: " + e.getMessage();
}
}
@Tool(name = "WriteFileTool",value = "Write content to a file")
public String writeFile(@P(value = "Name of the file to write") String fileName,
@P(value = "Content to write to the file") String content
) {
String filePath = FILE_DIR + "/" + fileName;
try {
// 创建目录
FileUtil.mkdir(FILE_DIR);
FileUtil.writeUtf8String(content, filePath);
return "File written successfully to: " + filePath;
} catch (Exception e) {
return "Error writing to file: " + e.getMessage();
}
}
}
|