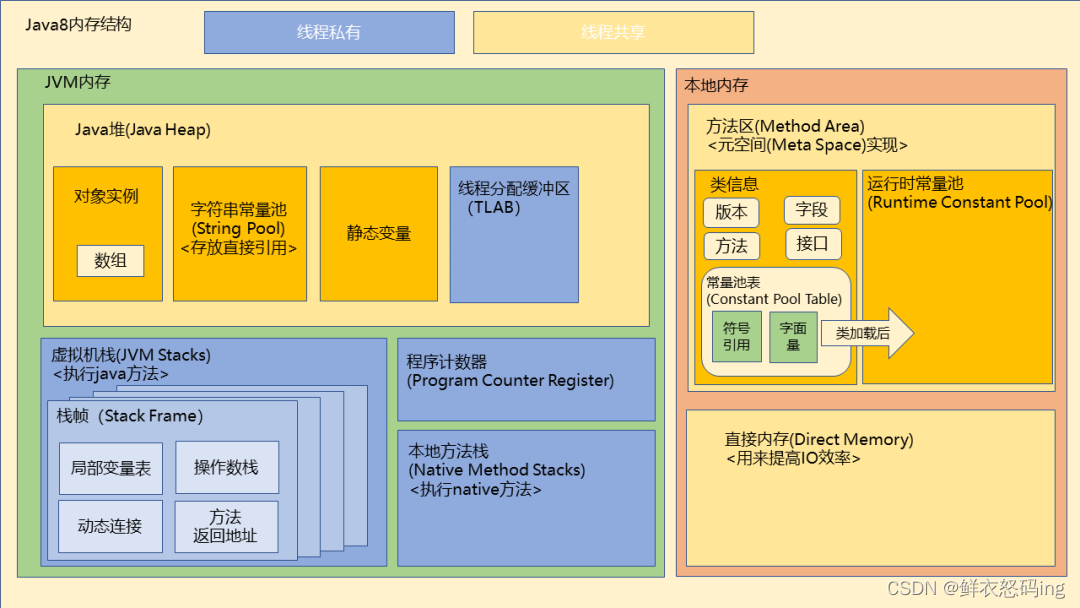
JVM8 结构图
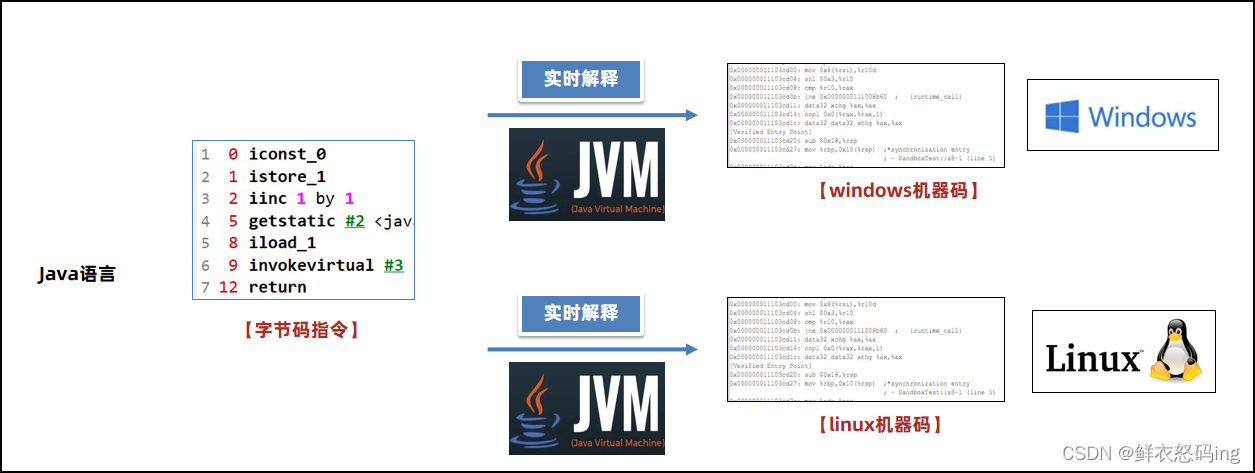
Java 性能低的主要原因
Java 语言如果不做任何的优化,性能其实是不如 C 和 C++语言的。主要原因是:
在程序运行过程中,Java 虚拟机需要将字节码指令实时 地解释成计算机能识别的机器码,这个过程在运行时可能会反复执行,所以效率较低。

C 和 C++语言在执行过程中,只需将源代码编译成可执行文件,就包含了计算机能识别的机器码,无需在运行过程中再实时地解释,所以性能较高。

Java 为什么要选择一条执行效率比较低的方式呢?主要是为了实现跨平台的特性。Java 的字节码指令,如果希望在不同平台(操作系统+硬件架构),比如在 windows 或者 linux 上运行。可以使用同一份字节码指令,交给 windows 和 linux 上的 Java 虚拟机进行解释,这样就可以获得不同平台上的机器码了。这样就实现了 Write Once,Run Anywhere 编写一次,到处运行。
字节码文件
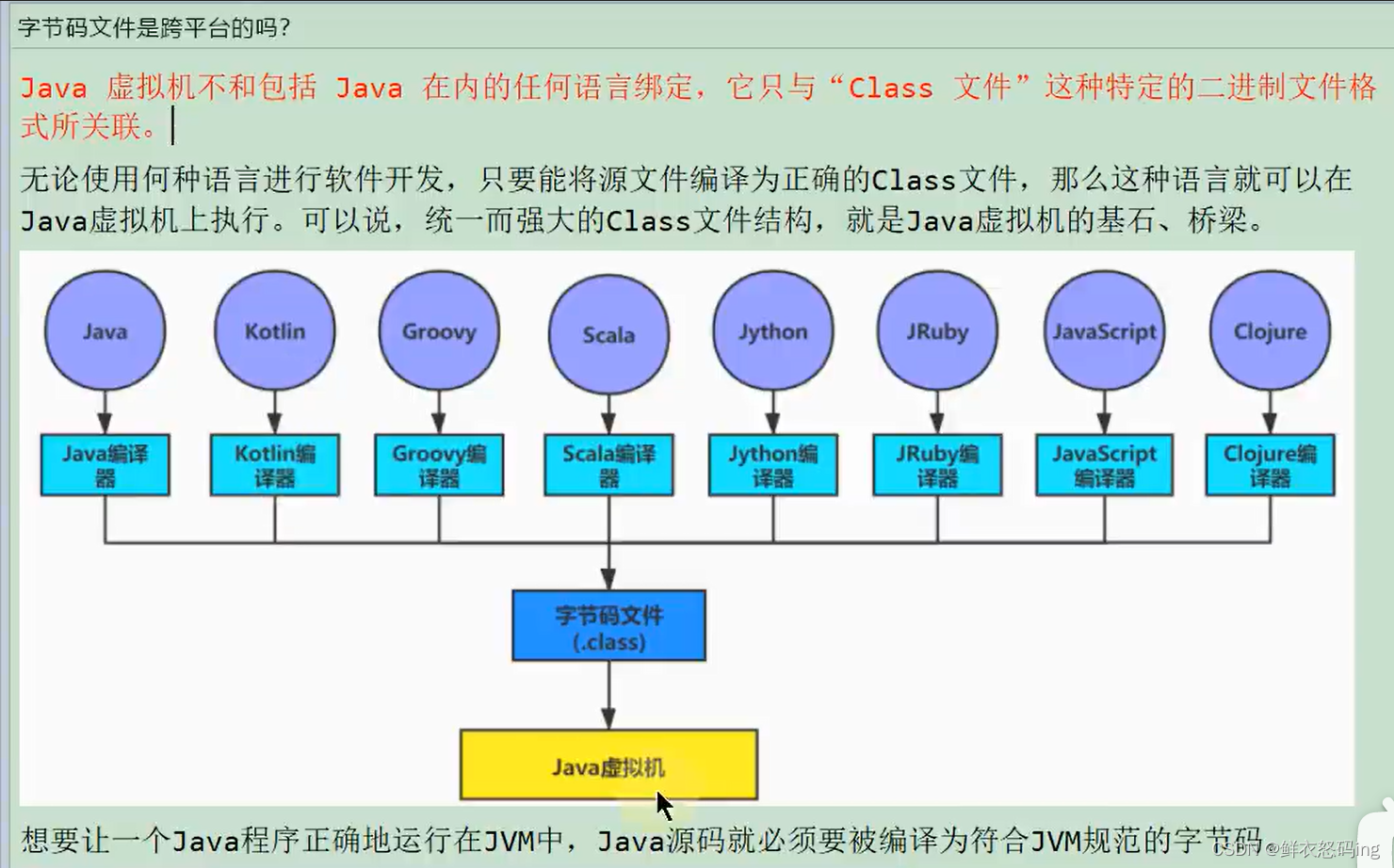
我们 java 中说的字节码文件即 java 代码编译后的.class 文件,class 文件可以跨平台运行在不同操作系统的 JVM 上。
字节码文件的组成
字节码文件总共可以分为以下几个部分:
基础信息:魔数、字节码文件对应的 Java 版本号、访问标识(public final 等等)、父类和接口信息
常量池:保存了字符串常量、类或接口名、字段名,主要在字节码指令中使用
字段:当前类或接口声明的字段信息
方法:当前类或接口声明的方法信息,核心内容为方法的字节码指令
属性:类的属性,比如源码的文件名、内部类的列表等
JVM 架构
根据上面的 JVM 图,JVM 大致可分为三块: 类加载器 ClassLoader、运行时数据区 、执行引擎
类加载器 ClassLoader
类加载器会通过二进制流的方式获取到字节码文件并交给 Java 虚拟机,虚拟机会在方法区和堆上生成对应的对象保存字节码信息。
根加载器(启动类加载器):
默认加载 Java 安装目录/jre/lib 下的类文件,比如 rt.jar,tools.jar,resources.jar 等。
扩展类加载器:
默认加载 Java 安装目录/jre/lib/ext 下的类文件
应用程序类加载器(系统类加载器):
默认加载的是项目中的类以及通过 maven 引入的第三方 jar 包中的类。
用户自定义类加载器
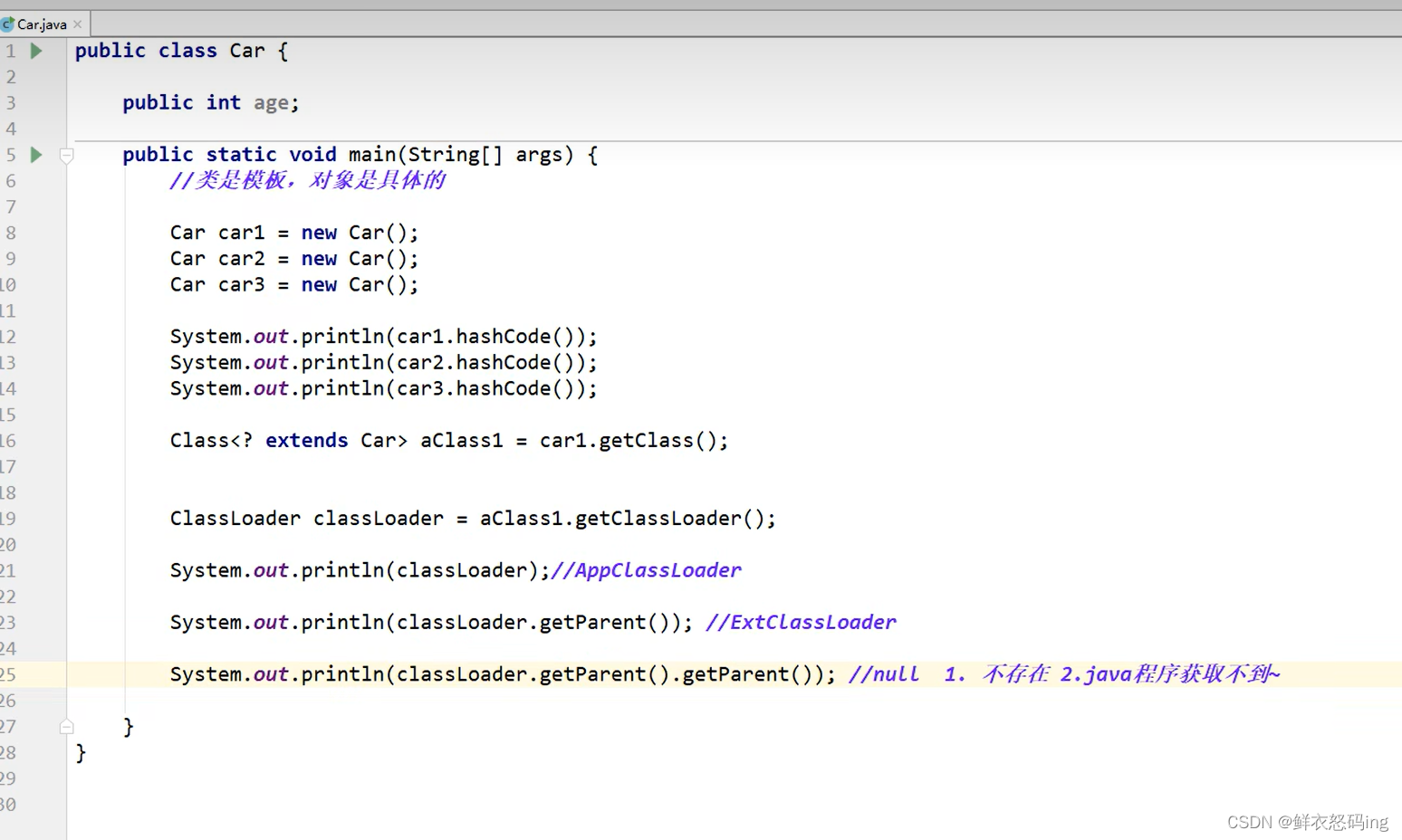
输出为 null 是因为根加载器的具体实现是由 C 或 C++编写,不在 java 范围内。
运行时数据区
运行时数据可以划分为以下 5 块
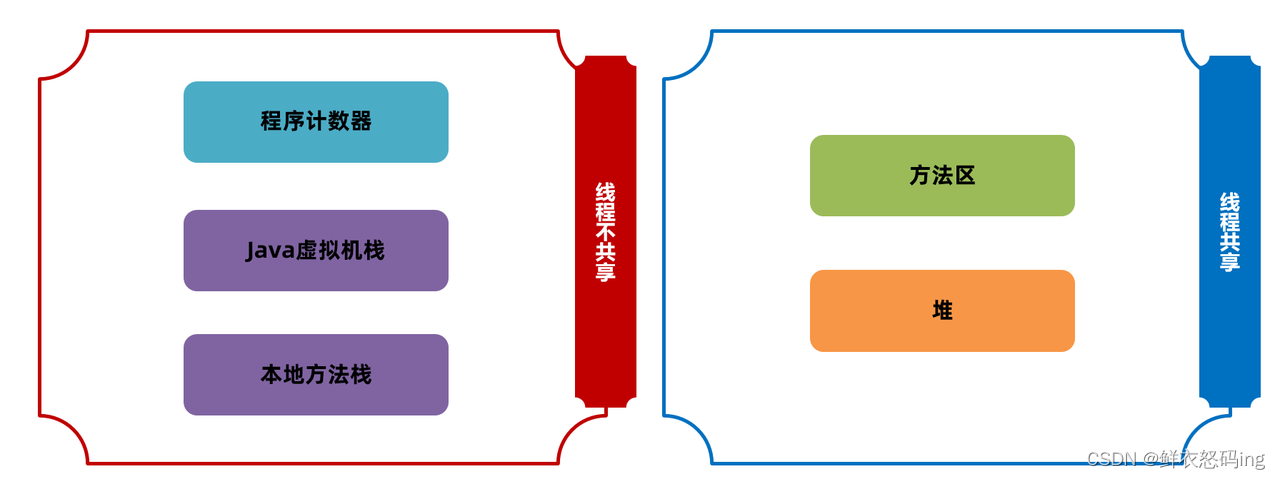
程序计数器
每个线程都有一个私有的程序计数器,也就是一个指针,指向方法区中的方法字节码(用来存储指向指令的地址)。解释器会在工作的时候改变这个计数器的值来选取下一条需要执行的字节码指令。如果线程执行的是非本地方法,则程序计数器中保存的是当前需要执行的指令地址;如果线程执行的是本地方法,则程序计数器中的值是 undefined。
Java 虚拟机栈(方法栈)
栈中没有垃圾回收的,线程结束后内存会自动释放。栈主管程序运行、生命周期、线程同步。
Java 虚拟机栈中是一个个栈帧,每个栈帧对应一个被调用的方法,当线程执行一个方法时,会创建一个对应的栈帧,并将栈帧压入栈中。当方法执行完毕后,将栈帧从栈中弹出。
栈帧及组成
局部变量表,局部变量表的作用是在运行过程中存放所有的局部变量
操作数栈,操作数栈是栈帧中虚拟机在执行指令过程中用来存放临时数据的一块区域
帧数据,帧数据主要包含动态链接、方法出口、异常表的引用
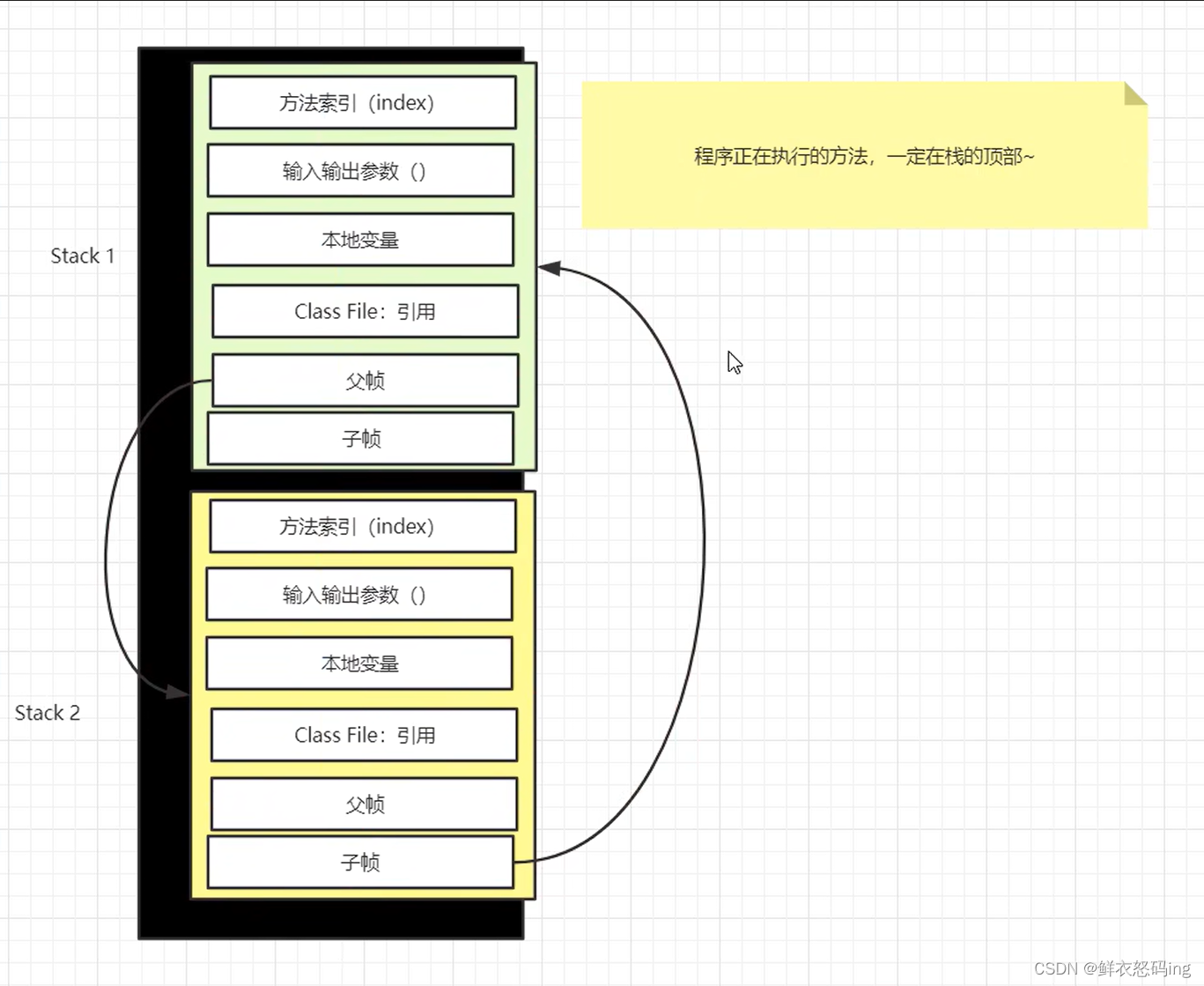
stack1 的方法结束后要弹出栈,此时需要通过 stack1 返回下面的 stack2 的方法。
本地方法栈
Java 虚拟机栈存储了 Java 方法调用时的栈帧,而本地方法栈存储的是 native 本地方法的栈帧
堆
|
|
这段代码中通过new关键字创建了两个Student类的对象,这两个对象会被存放在堆上。在栈上通过s1和s2两个局部变量保存堆上两个对象的地址,从而实现了引用关系的建立。
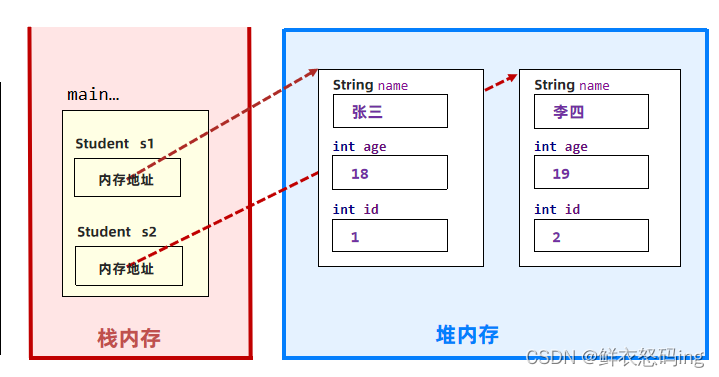
以前的 Java 中"几乎"所有的对象都会在堆中分配,但随着 JIT 编译器的发展和逃逸技术的逐渐成熟,所有的对象都分配到堆上渐渐变得不那么"绝对"了。从 JDK 7 开始,Java 虚拟机已经默认开启逃逸分析了,意味着如果某些方法中的对象引用没有被返回或者未被外面使用(也就是未逃逸出去),那么对象可以直接在栈上分配内存。垃圾指 JVM 中没有任何引用指向它的对象
逃逸分析
逃逸分析是一种编译器优化技术,用于判断对象的作用域和生命周期。如果编译器确定一个对象不会逃逸出方法或线程的范围,它可以选择在栈上分配这个对象,而不是在堆上。这样做可以减少垃圾回收的压力,并提高性能。
一个 JVM 实例只有一个堆内存,堆内存大小可以调节,类加载器读取类文件后要把类、方法、常变量放到堆内存中,保存所有引用类型的真实信息,堆内存在逻辑上分为三部分:
- 新生代:伊甸区、幸存 0 区 from、幸存 1 区 to
- 老年代
- 永久代

4.3 执行引擎
略
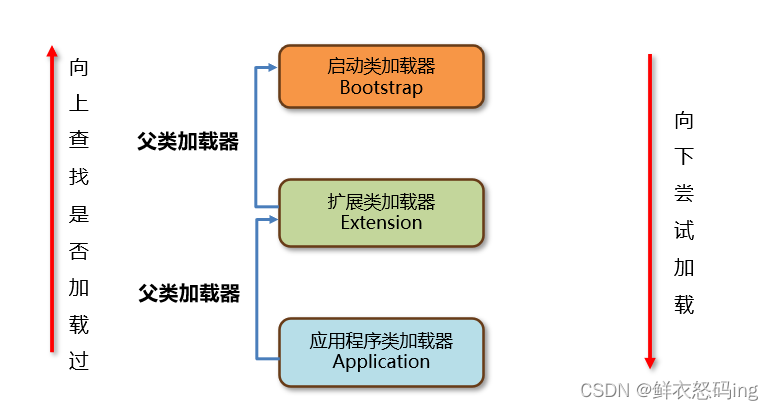
双亲委派
应用程序类加载器(又叫系统类加载器)收到类的加载请求先检查自己是否加载过该类,如果没有,将请求向上委托给自己的父类加载器(extensionLoader),如果父类加载器也没有加载过该类,该父类加载器继续向上委托给自己的父类加载器(bootstrapLoader,又叫根加载器、启动类加载器)若启动类加载器也没有加载过该类,则会根据要加载的类的全限定名尝试加载该类,若加载成功,则返回引用,若加载失败,则抛出异常,并反向委托给扩展类加载器,若仍加载失败,则继续抛出异常,并反向委托给应用程序类加载器,若仍加载失败,则报异常 ClassNotFound。

安全性和沙箱机制
由于 java 核心库和扩展库由根加载器加载,这些库中的类有更高的安全级别,而应用程序类由应用程序类加载器加载,安全级别低,双亲向上委派可以防止核心 API 被篡改,提高了程序安全性。
什么是沙箱?
java 安全模型的核心就是 java 沙箱,沙箱是一个限制程序运行的环境,沙箱机制就是把 java 代码限定在 jvm 的特定运行范围内,严格限制代码对本地系统资源的访问(CPU、内存、文件系统、网络等),通过这样来保证代码的有效隔离,防止对本地系统造成破坏。
避免类重复加载
由于父类加载器加载类时会优先尝试加载,若类已经被加载过,就不会再次加载,避免了类重复加载。
破坏双亲委派
打破双亲委派机制历史上有三种方式,但本质上只有第一种算是真正的打破了双亲委派机制:
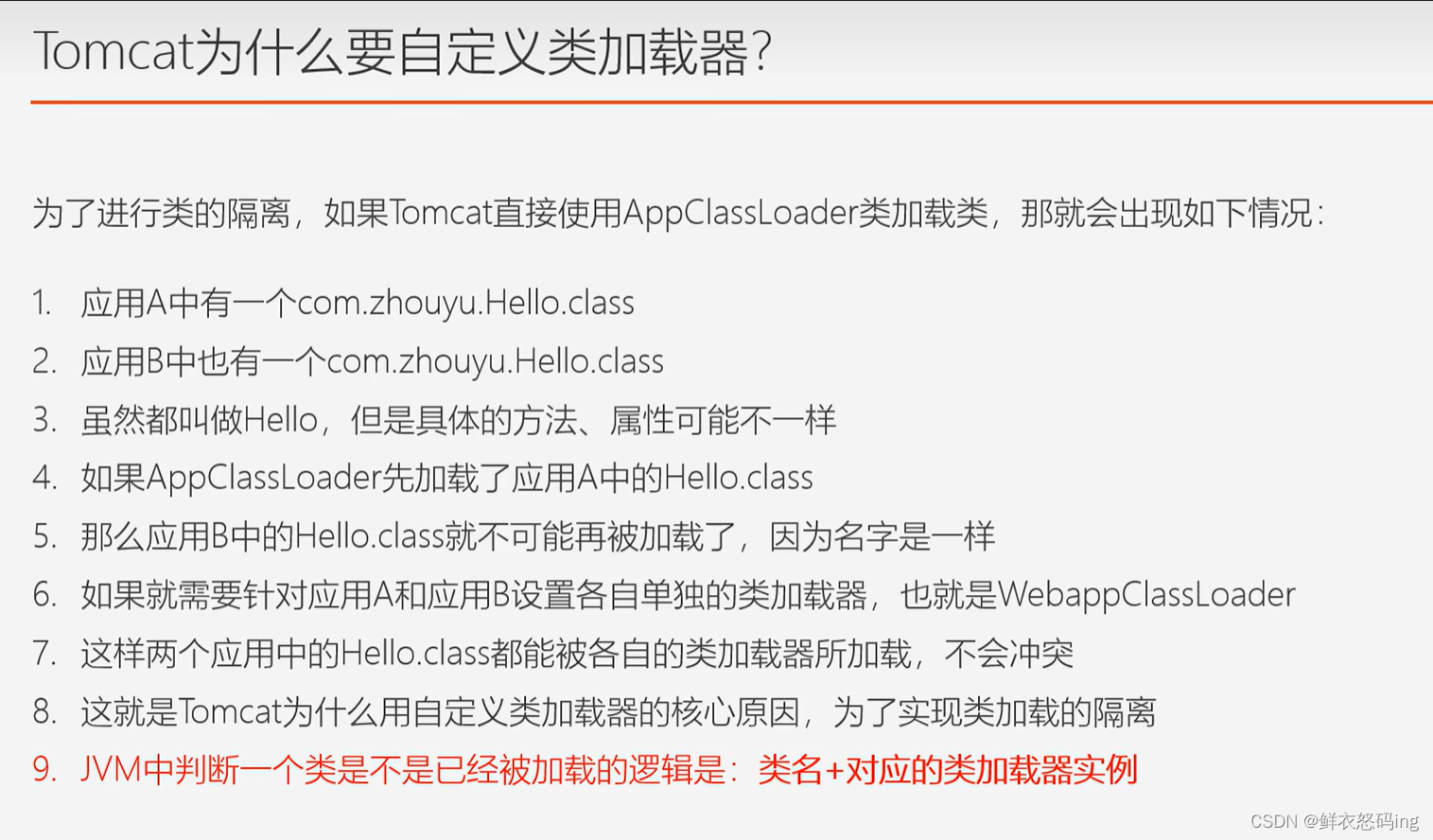
自定义类加载器并且重写 loadClass 方法。Tomcat 通过这种方式实现应用之间类隔离。
线程上下文类加载器。利用上下文类加载器加载类,比如 JDBC 和 JNDI 等。
Osgi 框架的类加载器。历史上 Osgi 框架实现了一套新的类加载器机制,允许同级之间委托进行类的加载,目前很少使用。
Tomcat 破坏
JDBC 破坏
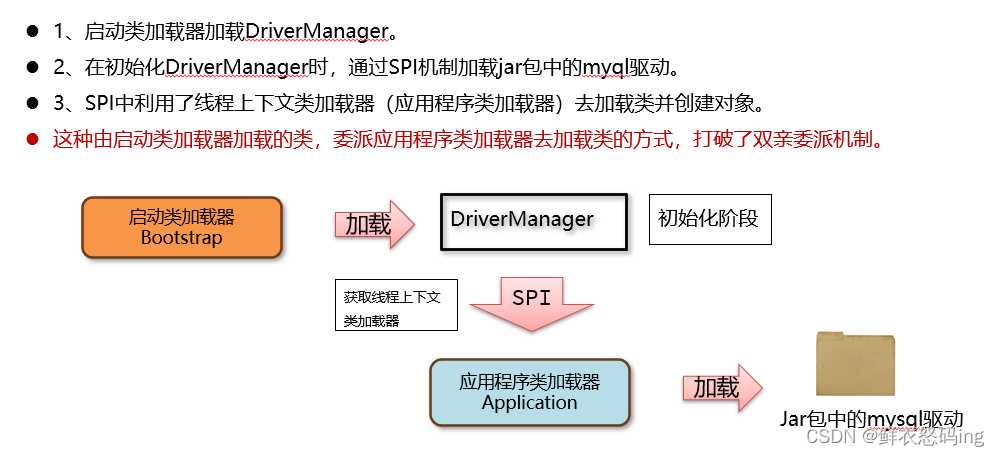
JDBC 中使用了 DriverManager 来管理项目中引入的不同数据库的驱动,比如 mysql 驱动、oracle 驱动。DriverManager 类位于 rt.jar 包中,由启动类加载器加载。依赖中的 mysql 驱动对应的类,由应用程序类加载器来加载。DriverManager 属于 rt.jar 是启动类加载器加载的。而用户 jar 包中的驱动需要由应用类加载器加载,_这就违反了双亲委派机制 。存疑
JDBC 案例中真的打破了双亲委派机制吗?
最早这个论点提出是在周志明《深入理解 Java 虚拟机》中,他认为打破了双亲委派机制,这种由启动类加载器加载的类,委派应用程序类加载器去加载类的方式,所以打破了双亲委派机制。
但是如果我们分别从 DriverManager 以及驱动类的加载流程上分析,JDBC 只是在 DriverManager 加载完之后,通过初始化阶段触发了驱动类的加载,类的加载依然遵循双亲委派机制。
所以我认为这里没有打破双亲委派机制,只是用一种巧妙的方法让启动类加载器加载的类,去引发的其他类的加载。