MySQL 是建立在关系模型基础上的关系型数据库,关系模型表明了数据库中所存储的数据之间的联系(一对一、一对多、多对多)。
字段类型
- TINYINT 占 1 字节,INT 占 4 字节,BIGINT 占 8 字节。
- CHAR 是定长字符串,VARCHAR 是变长字符串。CHAR 在存储时会在右边填充空格以达到指定的长度,检索时会去掉空格;VARCHAR 在存储时需要使用 1 或 2 个额外字节 记录字符串的长度,检索时不需要处理。CHAR(100)指的是 100 个字符而非字节
- MySQL 中字符的存储是与字符集(
CHARSET)相关的,具体的字节数取决于你使用的字符集和编码。latin1编码(单字节编码),每个字符占用 1 字节 。utf8mb4编码(变长编码),每个字符可能占用 1 到 4 字节,具体取决于字符的内容。
VARCHAR(100)和 VARCHAR(10)区别
VARCHAR(100)和 VARCHAR(10)都是变长类型,表示能存储最多 100 个字符和 10 个字符。但二者存储相同的字符串,所占用磁盘的存储空间其实是一样的,其所占用的磁盘空间是基于实际存储的字符长度,而不是字段的最大长度。
DECIMAL 和 FLOAT/DOUBLE 区别
DECIMAL 是定点数,可以存储精确的小数值。
FLOAT(4 字节),DOUBLE(8 字节) 是浮点数,只能存储近似的小数值。
DECIMAL 用于存储具有精度要求的小数,例如与货币相关的数据,可以避免浮点数带来的精度损失。
TEXT 和 BLOB
- TEXT 可以存储更长的字符串,即长文本数据,例如博客内容。
- BLOB 类型主要用于存储二进制大对象,例如图片、音视频等文件。
- TEXT 和 BLOB 缺点:
- 不能有默认值。
- 检索效率较低。
- 在使用临时表时无法使用内存临时表,只能在磁盘上创建临时表。
- 不能直接创建索引,需要指定前缀长度。
>
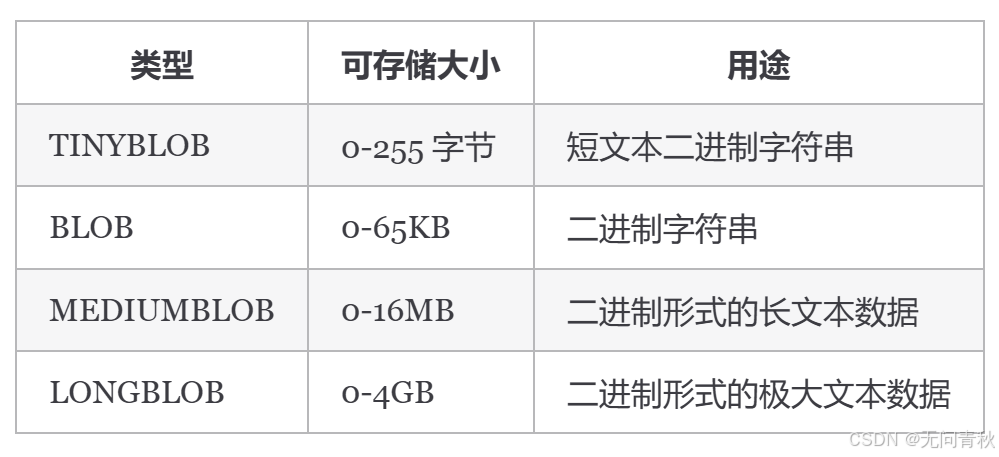
DATETIME 和 TIMESTAMP
DATETIME 类型没有时区信息,TIMESTAMP 和时区有关。
NULL 和"“的区别
NULL代表一个不确定的值,就算是两个NULL,它俩也不一定相等。例如,SELECT NULL=NULL的结果为 NULL''的长度是 0,是不占用空间的,而NULL是需要占用空间
为什么 MySQL 不建议使用 NULL 作为列默认值?
NULL会影响聚合函数的结果。例如,SUM、AVG、MIN、MAX等聚合函数会忽略NULL值,如果参数是某个字段名(COUNT(列名)),则会忽略NULL值,只统计非空值的个数。查询NULL值时,必须使用IS NULL或IS NOT NULLl来判断,而不能使用 =、!=、 <、> 之类的比较运算符。而''是可以使用这些比较运算符的。
Boolean 类型如何表示
MySQL 中没有专门的布尔类型,而是用 TINYINT(1) 类型来表示布尔值。TINYINT(1) 类型可以存储 0 或 1,分别对应 false 或 true。
MySQL 基础架构
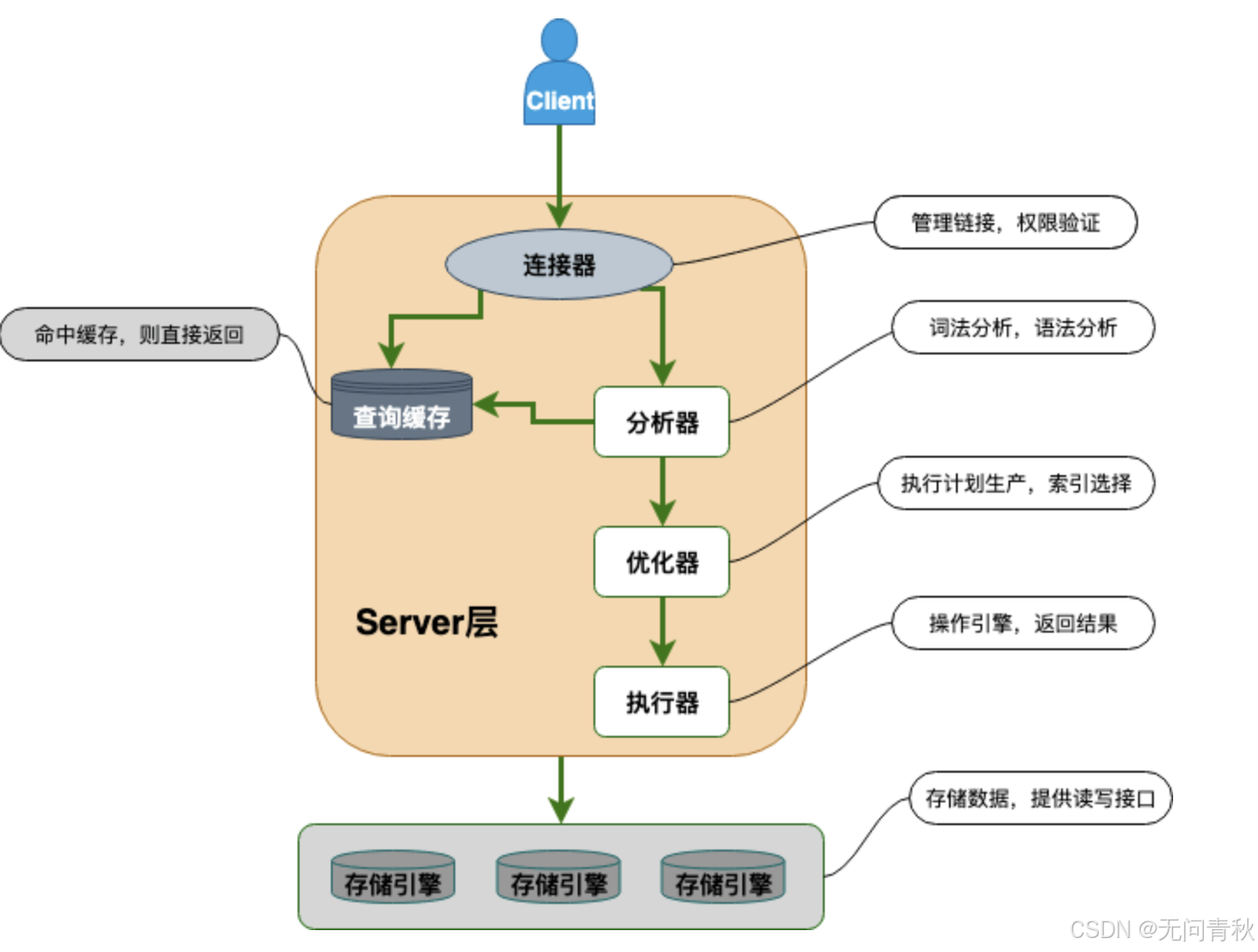
- 连接器: 身份认证和权限相关(登录 MySQL 的时候)。
- 查询缓存: 执行查询语句的时候,会先查询缓存(MySQL 8.0 版本后移除,因为这个功能不太实用)。
- 分析器: 没有命中缓存的话,SQL 语句就会经过分析器,分析器说白了就是要先看你的 SQL 语句要干嘛,再检查你的 SQL 语句语法是否正确。
- 优化器: 按照 MySQL 认为最优的方案去执行。
- 执行器: 执行语句,然后从存储引擎返回数据。 执行语句之前会先判断是否有权限,如果没有权限的话,就会报错。
- 插件式存储引擎 :主要负责数据的存储和读取,采用的是插件式架构,支持 InnoDB、MyISAM、Memory 等多种存储引擎。InnoDB 是 MySQL 的默认存储引擎,绝大部分场景使用 InnoDB 就是最好的选择。
MySQL 存储引擎
MySQL :: MySQL 8.0 Reference Manual :: 17 The InnoDB Storage Engine
MySQL :: MySQL 8.0 Reference Manual :: 18 Alternative Storage Engines
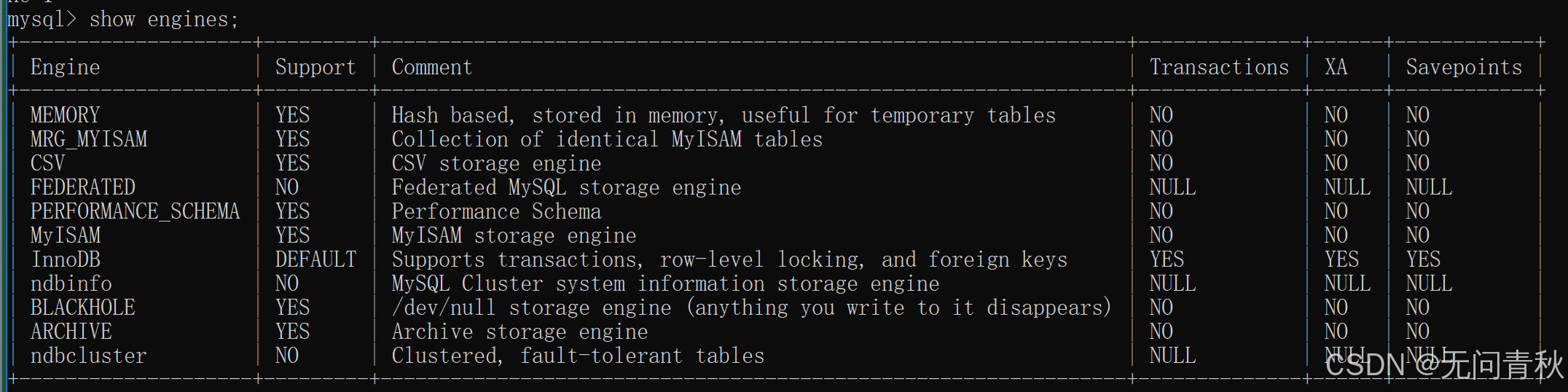
- MySQL 5.5.5 之前,MyISAM 是 MySQL 的默认存储引擎。5.5.5 版本之后,InnoDB 是 MySQL 的默认存储引擎。 在上述所有引擎中,只有 InnoDB 引擎支持事务。
- 上面还提到过 MySQL 存储引擎采用的是 插件式架构 ,支持多种存储引擎。存储引擎是基于表的,而不是数据库。
MyISAM 和 InnoDB 区别
锁: MyISAM 只有表级锁,而 InnoDB 支持行级锁和表级锁,默认为行级锁。对于并发操作,细粒度的行级锁性能肯定更好!
事务: MyISAM 不提供事务支持。InnoDB 提供事务支持,实现了四个隔离级别,分别是:读未提交、读已提交、可重复读、可串行化。InnoDB 默认是可重读,隔离级别是可以解决幻读问题发生的(基于 MVCC 和 Next-Key Lock)。
外键: MyISAM 不支持物理外键,而 InnoDB 支持物理外键。然而外键的维护对数据库性能也有一定影响,特别是分布式、高并发项目,一个字段的更新往往会引起其他字段的更新,极大拉低数据库性能,因此是不建议使用物理外键,而是逻辑外键(在代码中进行约束)
数据恢复 :MyISAM 不支持,而 InnoDB 支持。使用 InnoDB 的数据库在异常崩溃后,数据库重新启动的时候依赖redo.log使数据库恢复到崩溃前的状态。
MVCC: MVCC 可以看作是行级锁的一个升级,可以有效减少加锁操作,提高性能。MyISAM 显然是不支持 MVCC 的,毕竟连行级锁都没有。
索引: 都使用 B+Tree 作为索引结构,但是两者的实现方式不太一样。InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。
数据缓存策略和机制: InnoDB 使用缓冲池(Buffer Pool)缓存数据页和索引页,MyISAM 使用键缓存(Key Cache)仅缓存索引页而不缓存数据页。当数据库对数据做修改的时候,需要把数据页从磁盘读到 buffer pool 中,然后在 buffer pool 中进行修改 ,此时 buffer pool 中的数据页就与磁盘上的数据页内容不一致,如果这个时候发生 DB 服务重启,那么这些数据并没有同步到磁盘文件中(同步到磁盘文件是个随机 IO),就会发生数据丢失,如果这个时候,能够在有一个文件,当 buffer pool 中的数据页变更结束后,把相应修改记录记录到这个文件(记录日志是顺序 IO),那么当 DB 服务进行恢复 DB 的时候,可以根据这个文件的记录内容,重新持久化刷新到磁盘文件,保持数据的一致性。
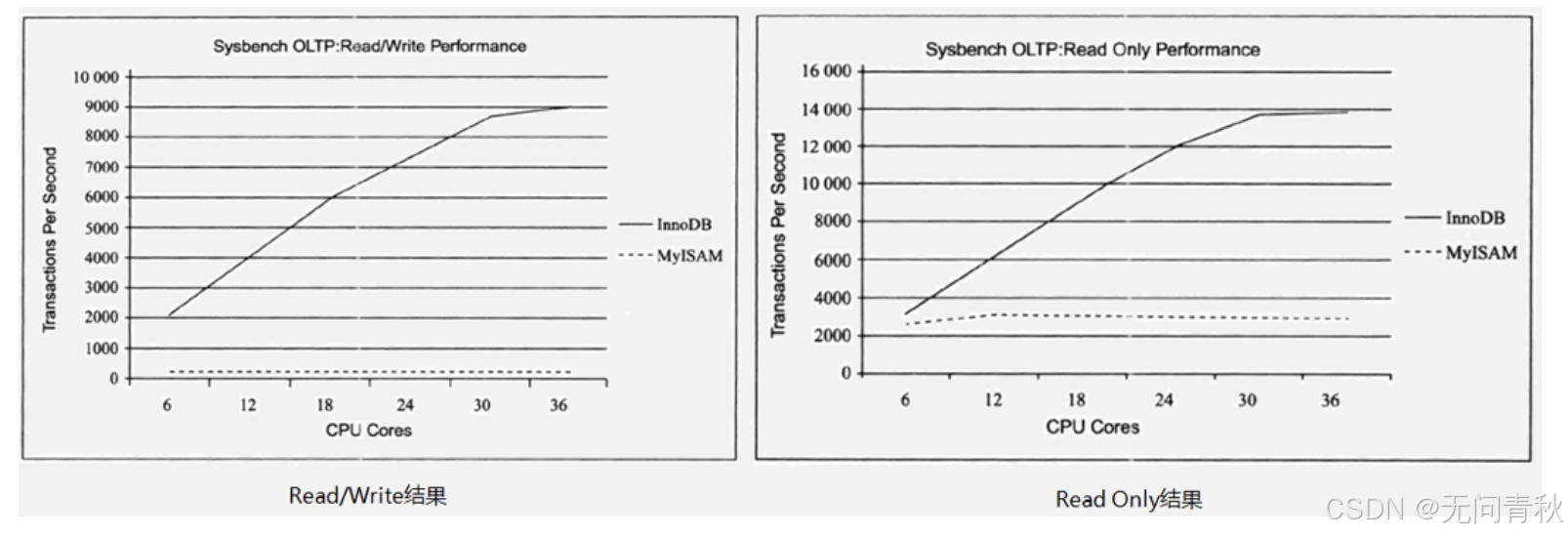
性能: InnoDB 的性能比 MyISAM 更强大,不管是在读写混合模式下还是只读模式下,随着 CPU 核数的增加,InnoDB 的读写能力呈线性增长。MyISAM 因为读写不能并发,它的处理能力跟核数没关系。
MySQL 如何存储 IP 地址
可以使用字符串存储,但是存储空间相对较大(每个字符占用 1 字节),每个 IP 占用空间为 7-15 个字节(1.1.1.1 占用 7 字节,100.100.100.100 占用 15 字节)。
对于 ipv4,其实是 4 字节 32 位的数字,可以将 IP 地址转换成整形数据存储,性能更好,占用空间也更小。
MySQL 提供了两个方法来处理 ip 地址
INET_ATON():把 ip 转为无符号整型 (4-8 位)INET_NTOA():把整型的 ip 转为地址插入数据前,先用
INET_ATON()把 ip 地址转为整型,显示数据时,使用INET_NTOA()把整型的 ip 地址转为地址显示即可。