数仓架构
数仓架构大致分为离线数仓架构和实时数仓架构,数仓架构可以简单理解为构成数仓的各层关系,如 ODS、DWM、DWD、DWS,具体分层这里不赘述。
离线数仓架构
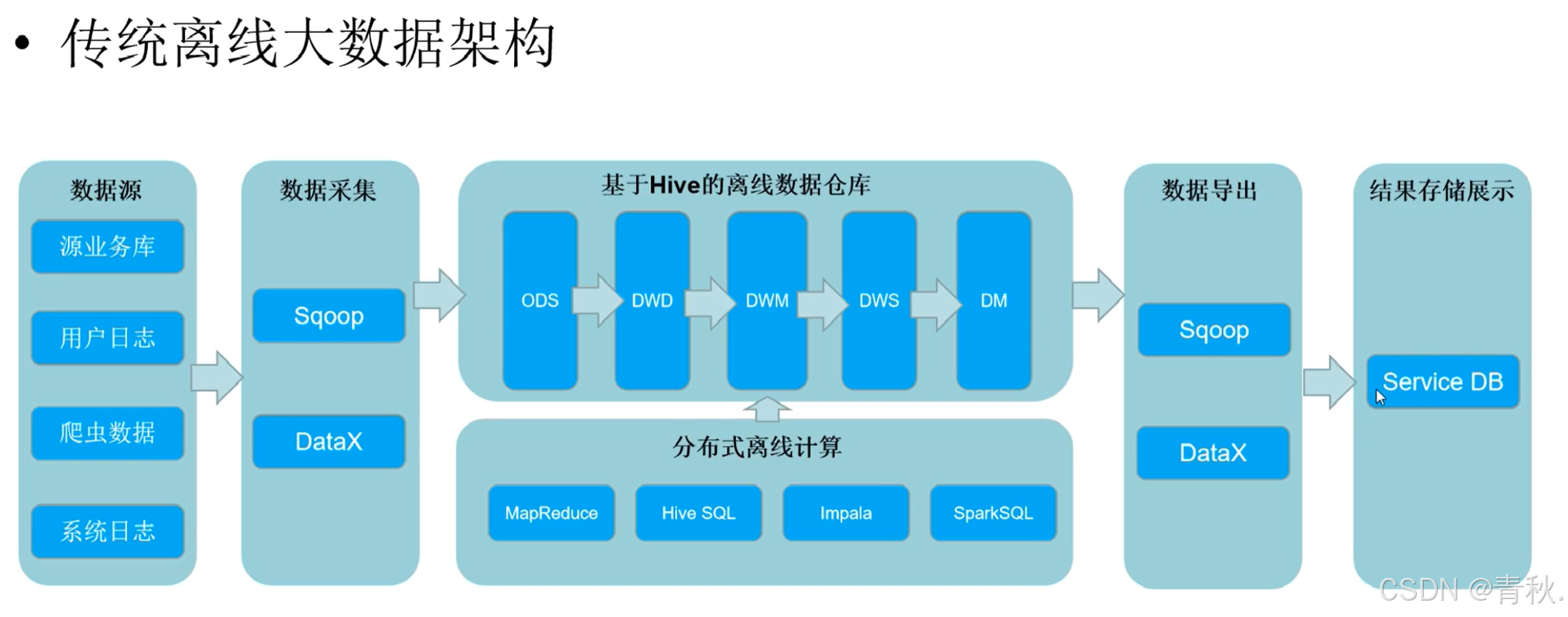
显而易见,这种架构不能处理实时数据,那么必然会有数据的流失。
任何事物都是随着时间的演进变得越来越完善,当然也是越来越复杂,数仓也不例外。
离线数仓架构 包括数据集市架构、Inmon 企业信息工厂架构、Kimball 数据仓库架构、混合型数据仓库架构,接下来就详细说说这几种架构。
数据集市架构
数据集市架构重点在于集市 二字,数据集市是按主题域 组织的数据集合,用于支持部门级的决策。有两种类型的数据集市:独立数据集市 和 从属数据集市。
独立数据集市
独立数据集市集中于部门所关心的单一主题域 ,数据以部门为基础,例如制造部门、人力资源部门和其他部门都各自有他们自己的数据集市。
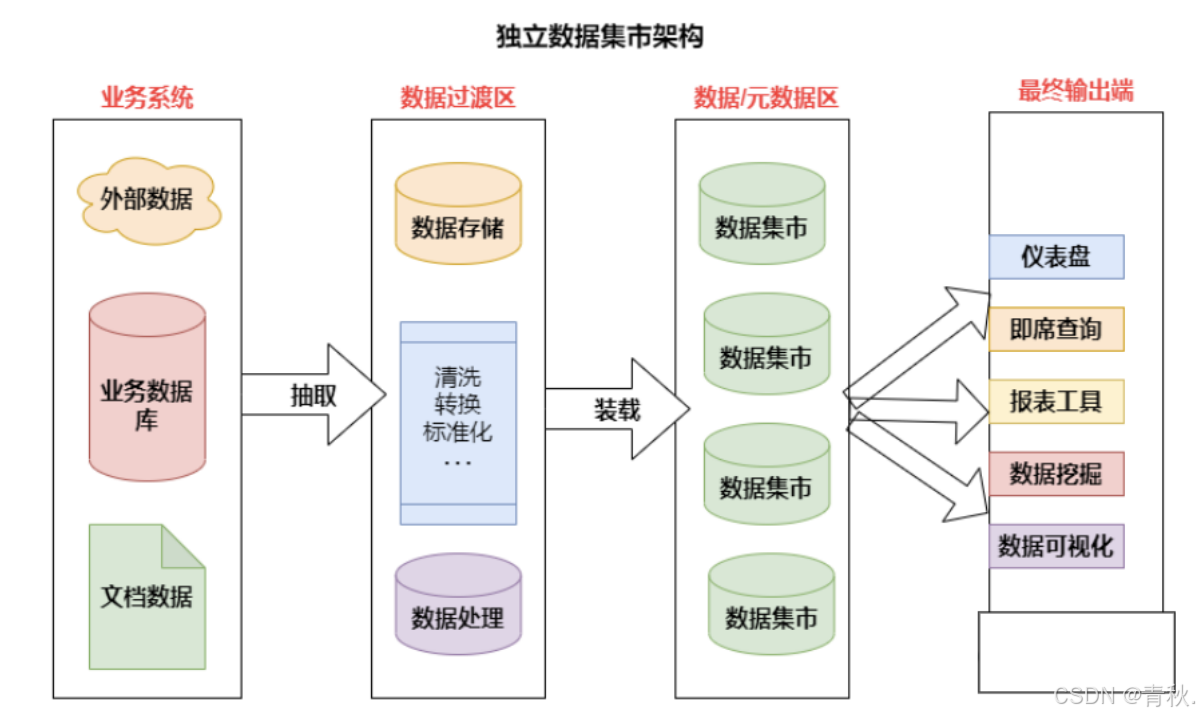
- 优点:因为一个部门的业务相对于整个企业要简单,数据量也小得多,所以部门的独立数据集市周期短、见效快。
- 缺点:独立数据集市各自为政。从业务角度看,当部门的分析需求扩展 或者跨部门跨主题域分析 时,独立数据市场会力不从心。 当数据存在歧义 ,比如同一个产品在 A 部门和 B 部门的定义不同,将无法在部门间进行信息比较。 每个部门使用不同的技术,建立不同的 ETL 的过程,处理不同的事务系统,而在多个独立的数据集市之间还会存在数据的交叉与重叠,甚至会有数据不一致的情况!
从属数据集市
从属数据集市的数据来源于数据仓库 从属数据集市的数据来源于数据仓库,即从属于数据仓库。
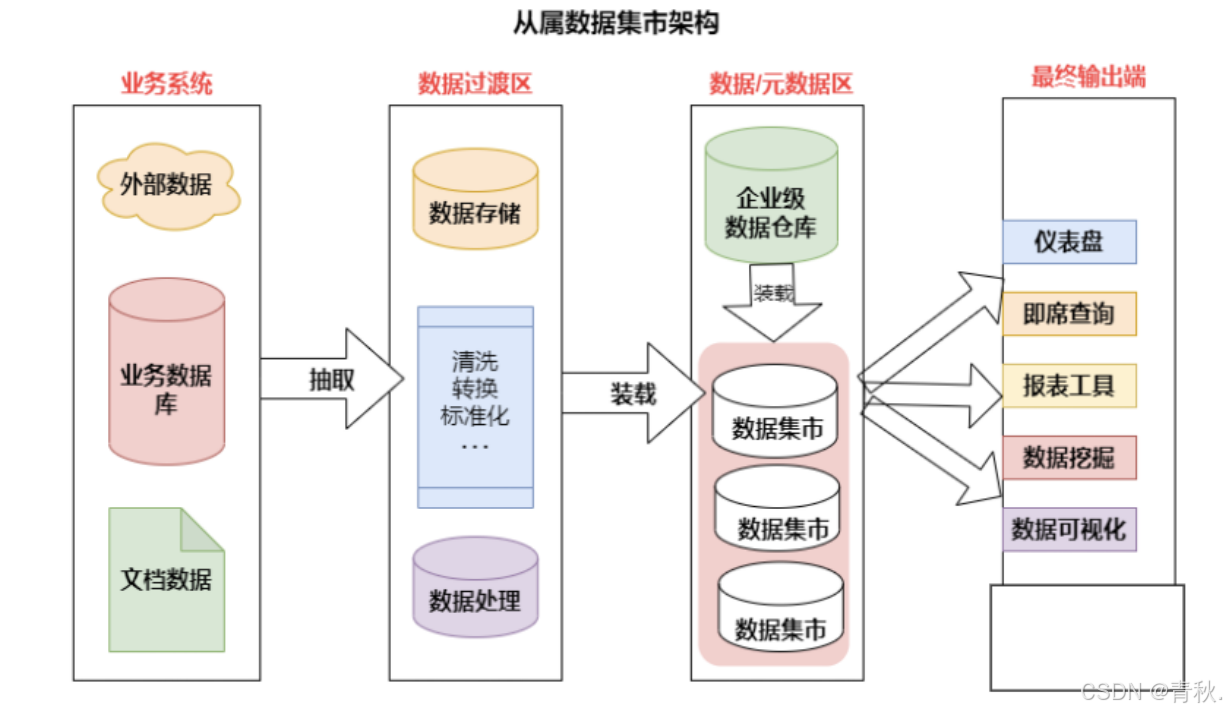 优点:
优点:
- 性能:当数据仓库的查询性能出现问题,可以考虑建立几个从属数据集市,将查询从数据仓库移出到数据集市。
- 安全:每个部门可以完全控制他们自己的数据。
- 数据一致:因为每个数据集市的数据来源都是同一个数据仓库,有效消除了数据不一致的情况。
Inmon 企业信息工厂架构
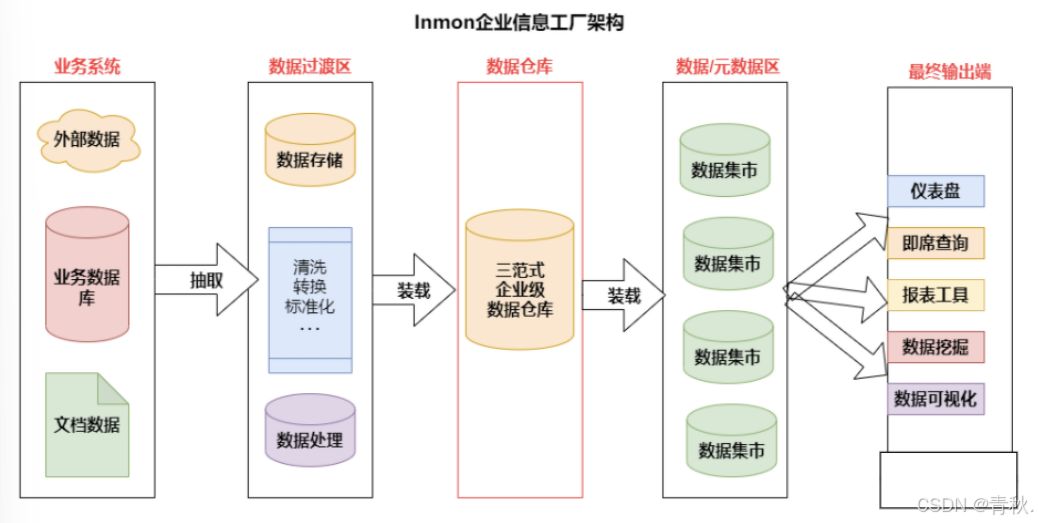
- Inmon 架构是范式建模
- 企业级数据仓库是企业级别的,正如 Inmon 数据仓库所定义的,企业级数据仓库是一个细节数据的集成资源库。其中的数据以最低粒度级别被捕获,存储在满足三范式设计的关系数据库中。
- 部门级数据集市是企业中部门级别的,是面向主题数据的部门级视图,数据从企业级数据仓库获取。数据在进入部门数据集市时可能进行聚合。数据集市使用多维模型设计,用于数据分析。重要的一点是,所有的报表工具、BI 工具或其他数据分析应用都应该从数据集市查询数据,而不是直接查询企业级数据仓库。
Kimball 数据仓库架构
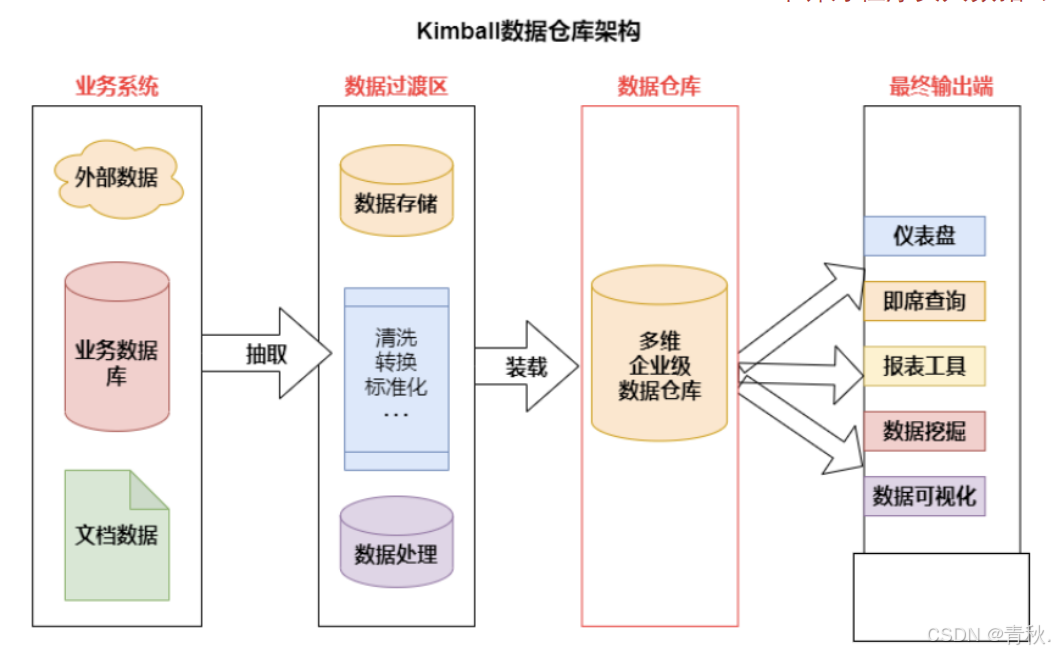
- 对比上一张图可以看到,Kimball 与 Inmon 两种架构的主要区别在于数据仓库的设计和建立。 Kimball 的数据仓库包含高粒度的企业数据,使用多维模型设计,是维度建模,这也意味着数据仓库由星型模式的维度表和事实表构成。分析系统或报表工具可以直接访问多维数据仓库里的数据。
- 在此架构中的数据集市也与 Inmon 中的不同。这里的数据集市是一个逻辑概念,只是多维数据仓库中的主题域划分,并没有自己的物理存储,也可以说是虚拟的数据集市。
混合型数据仓库架构
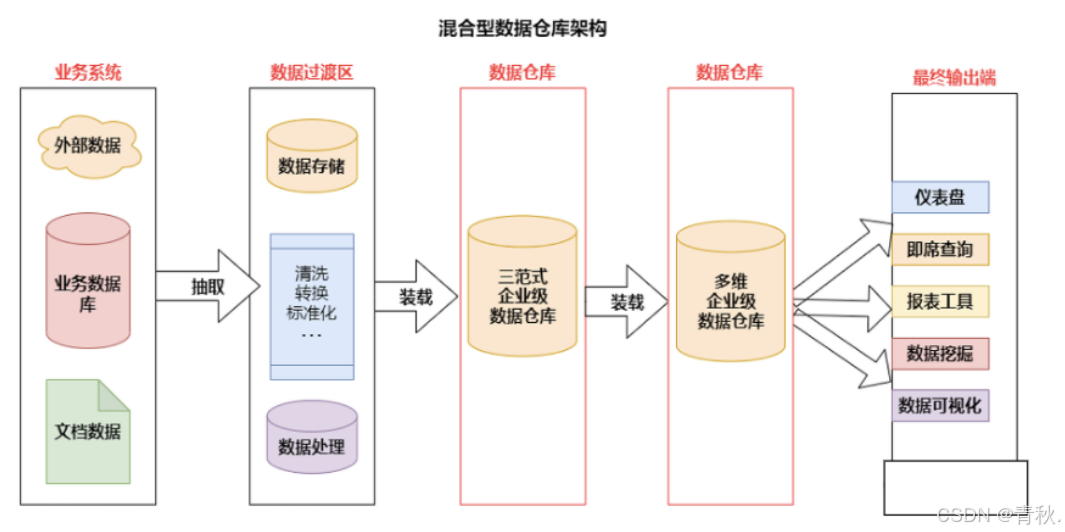
- 所谓的混合型结构,指的是在一个数据仓库环境中,联合使用 Inmon 和 Kimball 两种架构。
- 从架构图可以看到,这种架构将 Inmon 方法中的数据集市替换成了一个多维数据仓库,而数据集市则是多维数据仓库上的逻辑视图。
- 使用这种架构的好处是:既可以利用规范化设计消除数据冗余,保证数据的粒度足够细;又可以利用多维结构更灵活地在企业级实现报表和分析。
实时数仓架构
在某些场景中,数据的价值随着时间的推移而逐渐减少。所以在传统大数据离线数仓的基础上,逐渐对 数据的实时性提出了更高的要求。
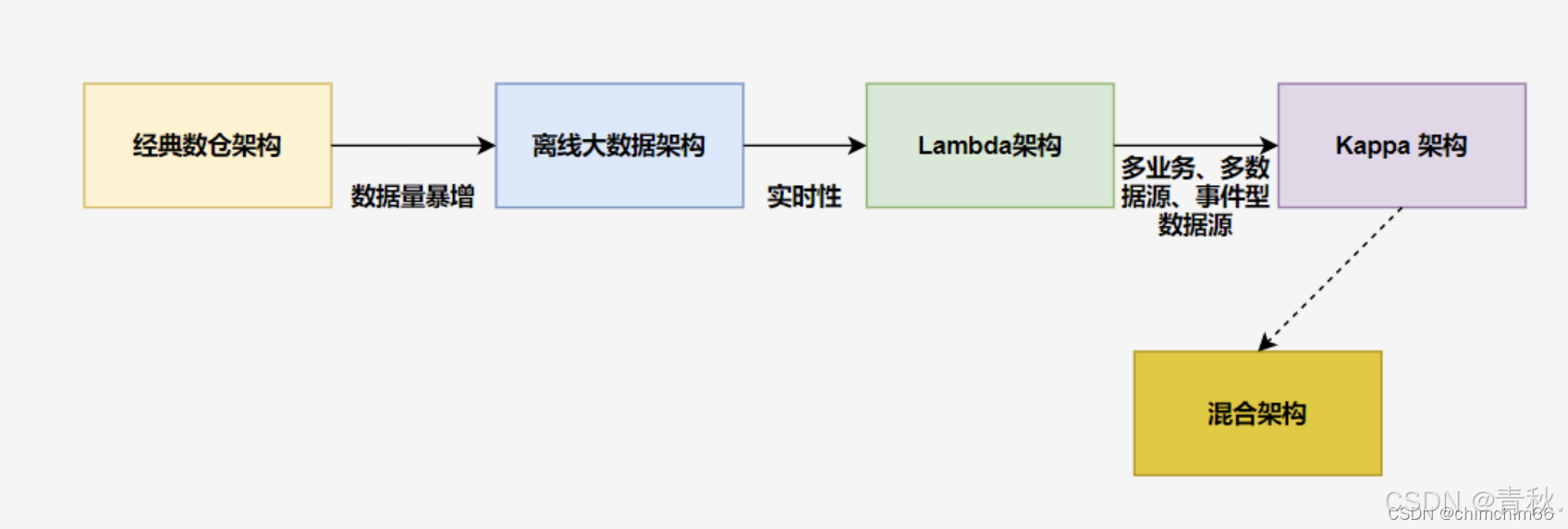
Lambda 架构
传统的 Lambda 实时开发
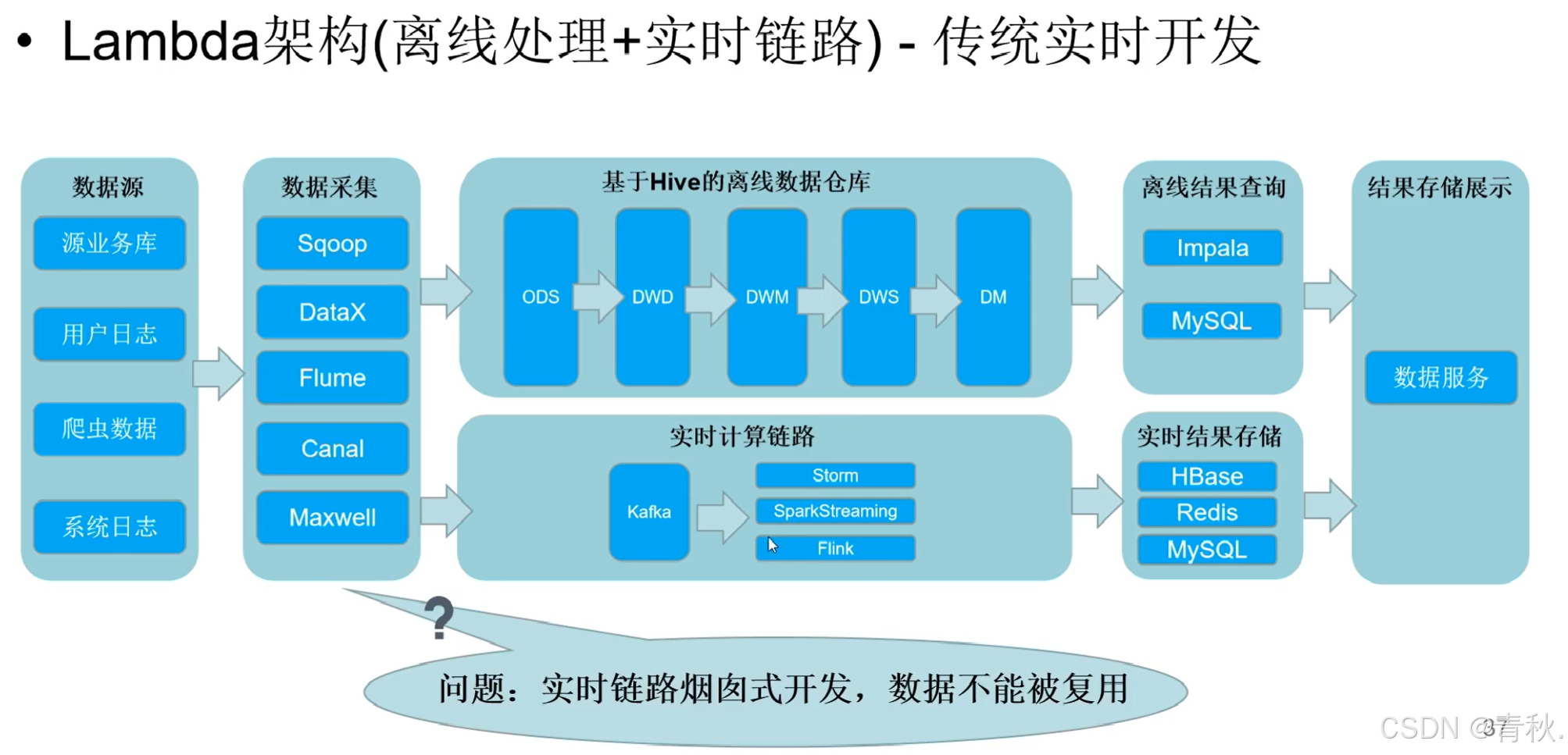
上述架构,在实时计算链路中,如果存在多个实时业务,每个业务都要对自己的数据进行数据清洗等操作,而数据清洗这操作是重复的。所以对其进行了如下优化,提高数据复用
升级的 Lambda 实时开发
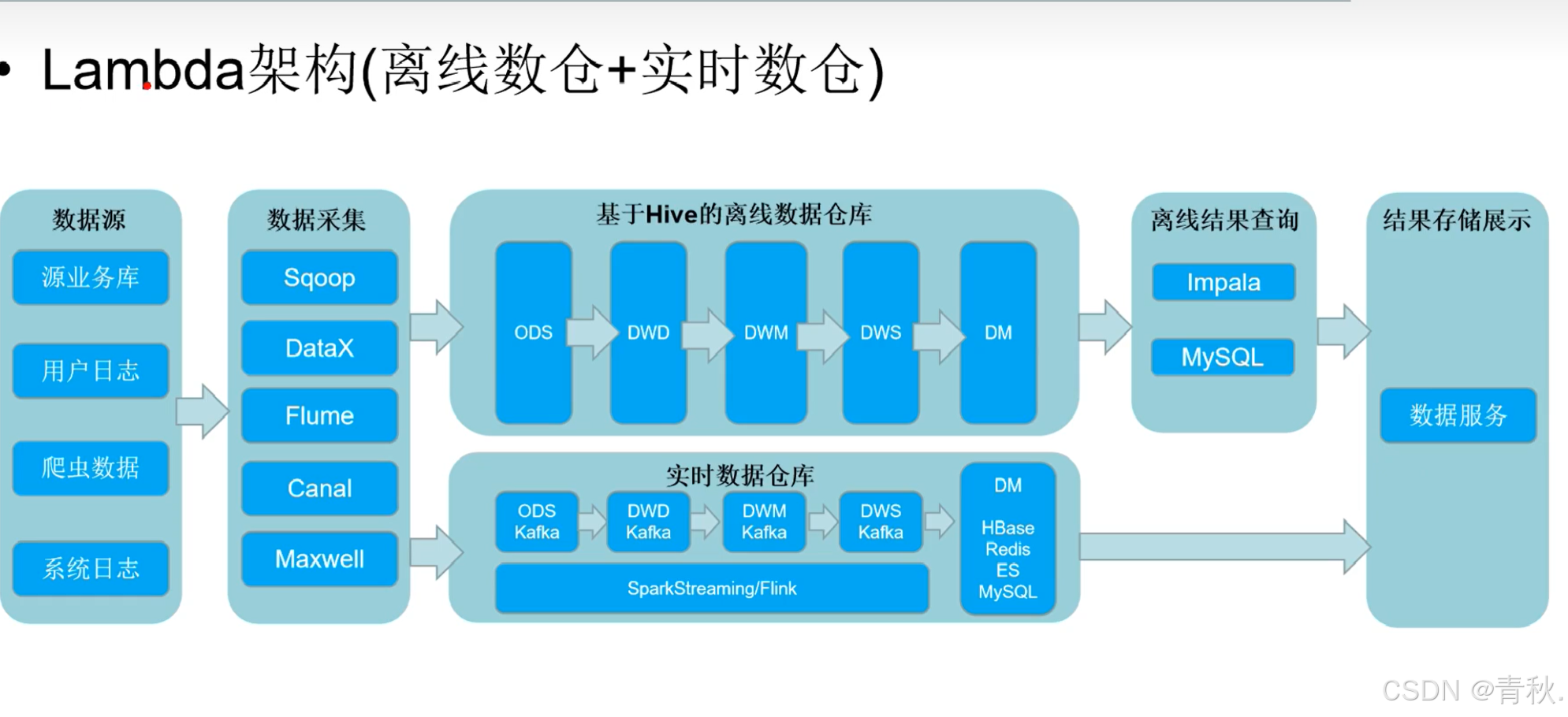
对实时链路进行数据分层,改成实时数仓,解决了数据复用的问题,可以对数据进行统一清洗等操作。
为什么 Lambda 架构同时存在流处理和批处理?
- 假如整个系统只有一个批处理层,会导致用户必须等待很久才能获取计算结果,一般有时间延迟。电商数据分析部门只能查看前一天的统计分析结果,无法获取当前的结果,这对于实时决策来说有 一个巨大的时间鸿沟,很可能导致管理者错过最佳决策时机。
- Lambda 架构属于较早的一种架构方式,早期的流处理不如现在这样成熟,在准确性、扩展性和容错性 上,流处理层无法直接取代批处理层,只能给用户提供一个近似结果,还不能为用户提供一个一致准确的结果。因此 Lambda 架构中,出现了批处理和流处理并存的现象。
Lambda 架构缺点
不管是传统的还是升级后的 Lambda 架构,严格来说并**不是纯正的实时数仓,而是离线+实时!**这就导致 Lambda 有如下缺点:
- 同样的需求要开发两套一样的代码,比如批处理要统计昨天一天的人数,流处理要统计实时在线人数,都是统计人数,却要开发两套代码。
- 跑两套相同的代码,集群资源使用增多
- 离线结果和实时结果可能不一致,当然以离线为主
- 离线批量计算 T+1 可能算不完,数据量大
- 服务器存储压力大
既然离线数仓占用计算压力大,存储压力大,那就不使用离线,使用纯实时的 kappa 架构
Kappa 架构
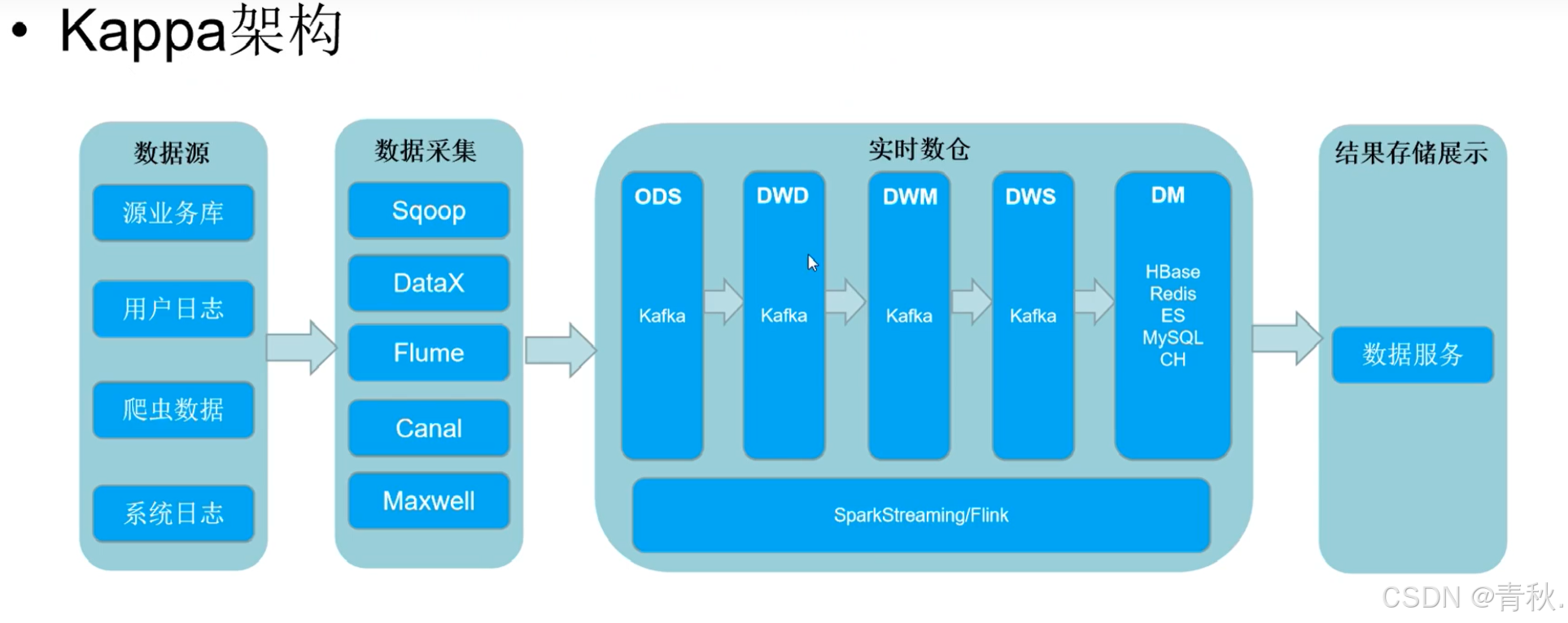
Kappa 架构缺点
- 只支持流处理,没有批处理
- 使用 kafka 进行消息缓存,kafka 不支撑海量数据存储,数据存储也有时间限制
- kafka 不支持 OLAP,即无法用 SQL 语句进行简单的数据校验
- 无法复用数据血缘管理体系(数据治理),因为 kafka 没有 schema 那种字段
- kafka 中的数据是 append 追加,不支持数据的更新、插入
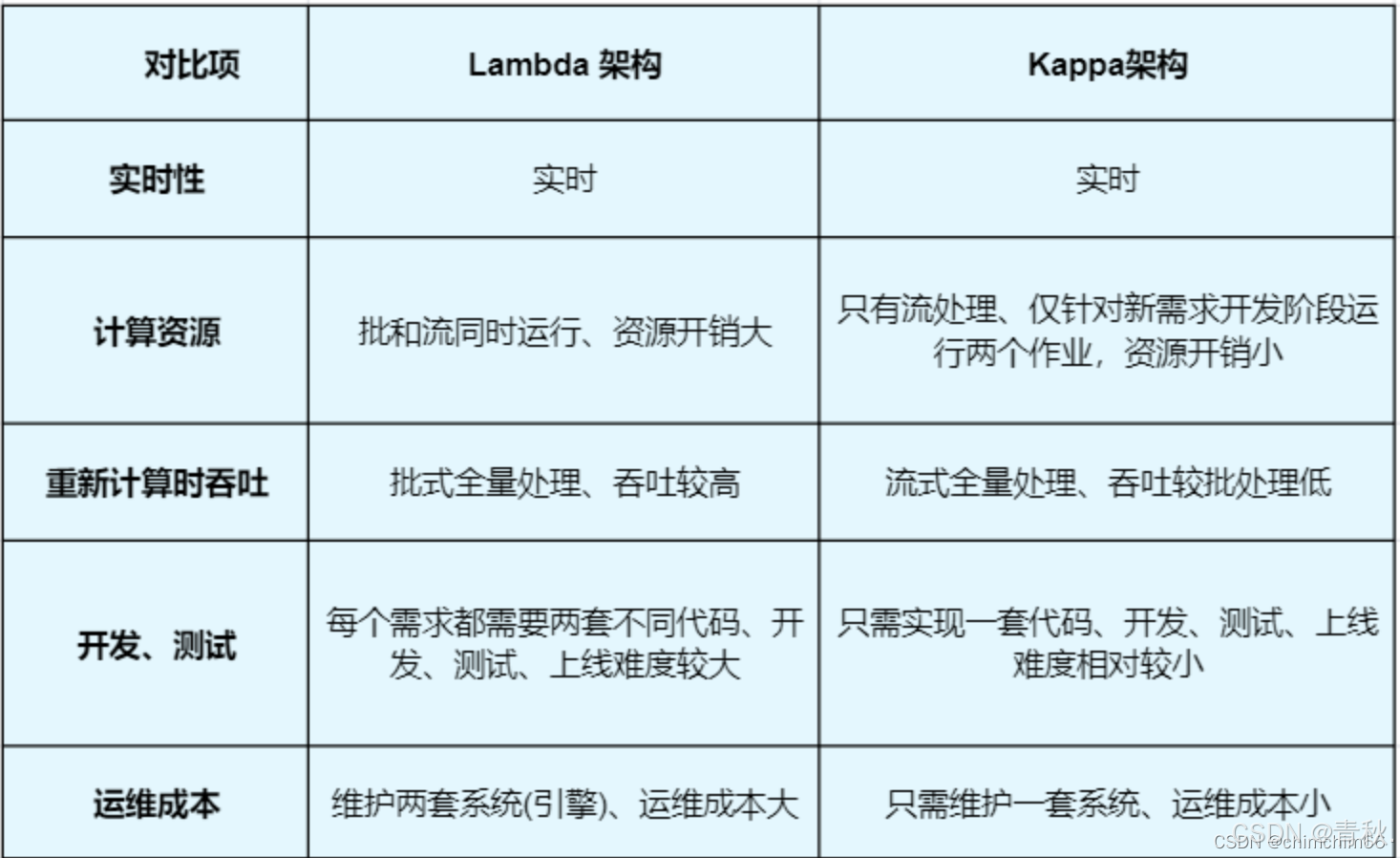
Kappa 和 Lambda 对比
湖仓一体—数据湖
基于 Lambda 和 Kappa 架构的缺点,出现了批流一体
- 从架构角度来看类似 Lambda 架构,批流一体既可以处理批数据,又可以处理流数据;
- 从计算框架角度来看,就是 flink、spark 框架,既支持批处理,又支持流处理;
- 从 SQL 角度来看,就是数仓各层统一支持 SQL,这就弥补了 kappa 中 kafka 不支持 SQL 的缺点;
- 从存储层面来看,能做到海量数据的存储,而不是像 kappa 一样存储在 kafka 缓存中;
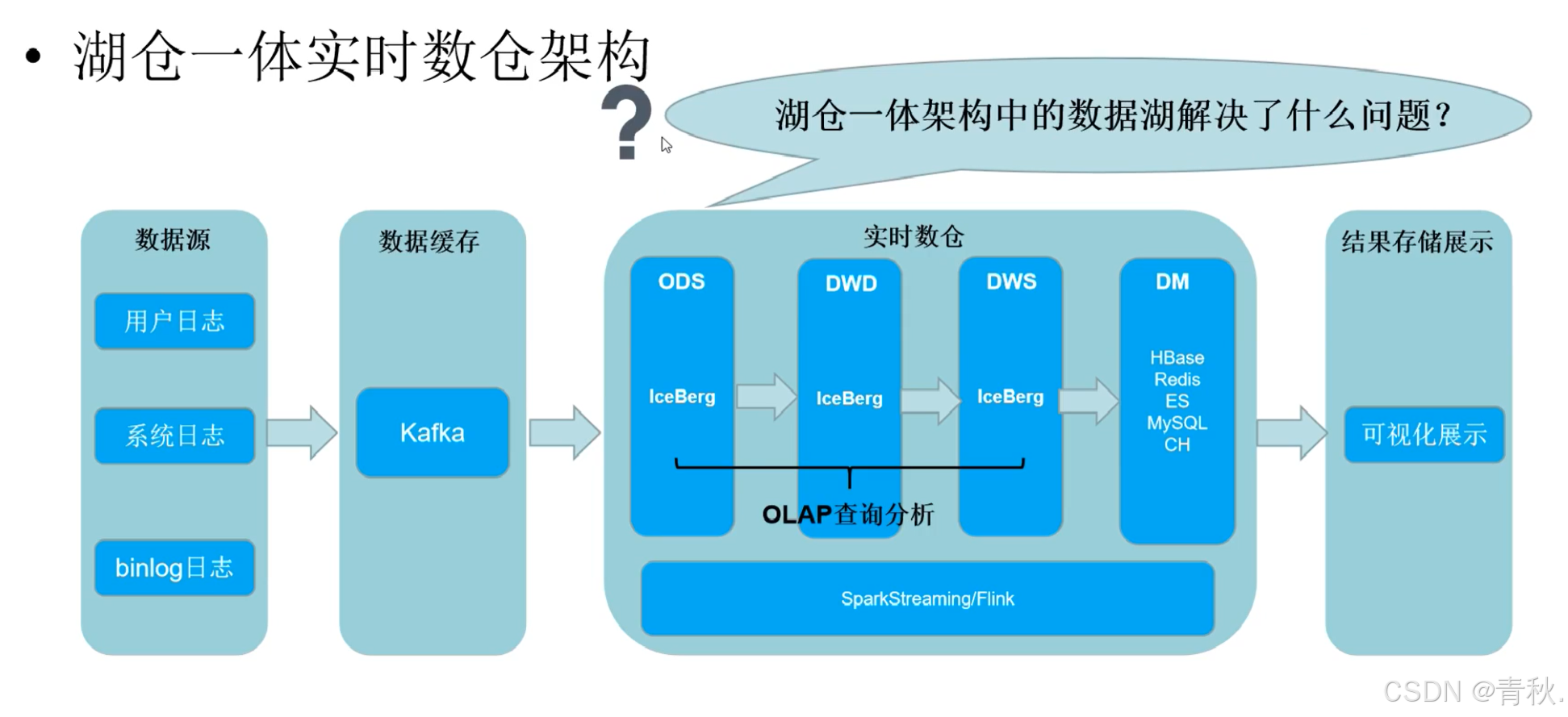
Kafka 换成了 Iceberg,IceBerg 就是数据湖技术的一种,介于上层计算引擎和底层存储格式之间的一个中间层,我们可以把它定义成一种“数据组织格式”,底层存储还是 HDFS。除此之外数据湖还有 Hudi(发展最完善)这里不具体阐述。
数据湖支持 SQL 查询,解决了如下问题:
- 存储统一
- 底层存储是 HDFS,解决了 kafka 存储量小,数据有时间限制的问题
- 任意分层都可以 OLAP(支持 SQL 查询)
- Iceberg 有 Schema 概念,可以追踪数据的血缘关系(数据治理)
- 支持数据实时更新,数据可以 update/insert